(大连外国语大学,辽宁 大连 116000)
一、引言
在信息时代中,互联网深刻改变了人们的生活和工作,它给人们提供了开展工作、表达自我的平台,短短数十年间,在互联网上产生的自然语言文本数量就远远超过了人类历史发展中所有保存下来的语言文本总和。这些文本以各种各类语言为载体,为我们提供了“规模最大,可公开获取的,自发生成的真实语言文本集合。具有可机读、多语种、即时性、语料真实、规模庞大、自我更新等特点,堪称一个取之不尽的语料富矿”①。近年来,随着数据挖掘技术、大数据技术的不断发展,通过现代技术手段,发掘网络自然语言文本资源,依托网络作为主要来源,构建专业的语料库成为了研究热点,这些语料库具有着资源丰富、获取便捷、存储方面、利用范围广泛等诸多优点,它们可以为语言学研究、语言教学与学习、人工智能、商业应用等诸多领域提供资源,本文以网络文本资源为对象,探讨建设多语种资源库,该资源库主要为区域国别等学科的教学、研究和学习提供资源支撑,在实践中具有重要的应用价值。
二、多语种网络文本资源库介绍
多语种网络文本资源库的概念源自于网络驱动型语料库(Web Driven Corpus),是一种针对网络自然语言文本采集与利用的新型资源库,与传统语料库无论在采集、存储、规模、分析、使用等各个方面都有所区别,相对于传统的语料库而言,多语种网络文本资源有以下几个重要优点:(1)以网络自然语言文本为主要采集对象;(2)较传统语料库数据量要大几个数量级,涵盖面广、更新及时;(3)主要以网络自动抓取为主,建库耗时短、成本低;(4)数据在本地可供用户使用,并且可以用语言对其进行后处理,并使用其首选工具进行查询②。相较传统语料库,它又有以下不足:(1)准确性和代表性相对于经过人工加工的传统预料库而言有所不足,尽管通过数据清洗的方法可以去除大部分数据噪声,但是自动生成的冗余内容或拼写错误依然会存在;(2)版权问题依然不清,语料库的推广会受到版权制约③。
多语言网络文本资源库建设目标是基于网络自然语言文本资源,采集对象国家的语言网络文本,分类构建多语种资源库,存储在本地硬盘或者网络云端之中,满足教师、学生利用自己熟悉的分析工具对语言对象国原始文本进行查询、分析,从而提升区域国别学科的教学、科研、学习能力。
三、网络数据采集方法
(一)网络数据采集原理
网络数据采集是建库中的重点工作,一般分为以下步骤:1.将要采集的网页地址存入网址列表(URL采集池);
2.确定要提取的内容,并设置筛选条件;
3.采集软件的配置,包括链接延时、采集者信息等;
4.运行采集软件,
目前,全球互联网中充斥着数万亿个网页,这些网页内容名目繁多、形式各异,如何能最有效率的匹配要搜索的内容是非常关键的,这就需要根据一定的机制来将时间成本和资源成本降至最低,我们通常将用下面公式表示:
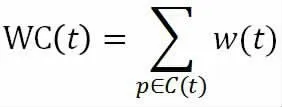
式中,WC在t时间内采集认为的最大加权完成率,其中C(t)和W分别表示在t时间内的采集页面数和权重函数,确定每个页面相对于搜索目标的相关性④。
采集器的设计无论采用何种计算机语言搭建,一般都包括待采集URL池、DNS解析模块、抓取模块、分析模块、URL去重模块等五个部分,其基本架构如图1所示:
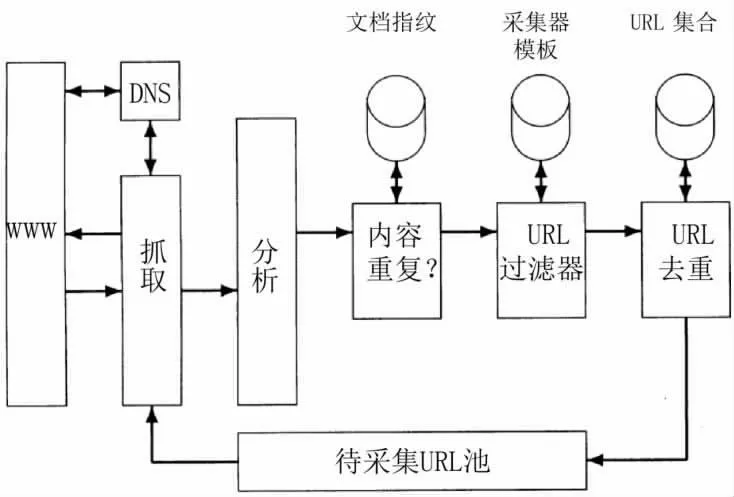
图1 采集器的基本构架
图1所示的采集器的工作原理是设定一个或者多个URL为采集的种子集合,接着,从种子集合中选择一个URL进行采集,然后对采集到的页面进行分析,并抽取出页面中的文本和链接(每个链接都指向其他的URL)。抽取出的文本输给文本索引器,而抽取出的URL则加入到待采集URL池中,任何时URL池中放的都是所有待采集网页的URL。一旦某个URL被采集,那么就从池中删除这个地址,整个采集过程可以看成是Web图的遍历过程。
(二)网络数据采集实践
多语言网络文本资源库数据采集过程中主要针对Python软件来进行开发,主要运用的模块有Scrapy、Requests、Beautifulsoap、Selenium等,在实际运用中根据网页页面的结构来进行选择,一般静态页面多使用Requests来发送请求,大批量的采集一般使用Scrapy等框架爬虫来进行采集,而对于网页较复杂的或者动态较多的页面则使用Selenium来进行采集,这些模块都有各自的优缺点,再使用中会根据使用需求来进行选择。选择合适的采集模块后,会进行相应的代码编写。以Requests模块为例,首先应该对页面进行分析,找出多页面之间的跳转机制,根据页面跳转机制编写代码,获取所有目标页面的网址数据;接下来再编写内容页代码块,提取所页面中所需要的内容信息;必要时要设置重复数据检查机制,自动过滤掉重复的网址或者页面内容。
在网络数据的采集过程中常常会遇到的问题是目标服务器会识别采集程序并对本机IP地址进行封禁,解决的办法一是引入代理服务器的机制,可以编写专门的代理服务器获取代码获得免费的代理服务器网址或者购买代理服务器网址,这样就达到了不断更换IP进行采集的目的;另外的解决办法是通过降低目标服务器的连接频率和速度,降低目标服务器运行的压力等措施。
总体来说,推荐使用第二种解决方法,在不影响目标服务器正常运行的情况下来进行数据采集,做文明的数据采集者。在网络采集中遇到另一个问题是如何保证采集的速度或效率,区别于传统的单机采集器,我们可以将采集程序布置到服务器端,并设置定时采集方法,如果需要我们还可以构建服务器分布采集系统,来达到提高采集效率的目标。最后,由于我们要进行多语种的文本数据采集,在文本编码格式上要特别注意选择合适的文本编码,已避免乱码的出现。
四、数据清洗与存储
(一)数据清洗
网站内容采集以后,接下来的工作是进行数据清洗,数据清洗第一个目的是去除噪声,噪声主要包括页面中的网络标记符号,网页的页眉、页脚,导航栏,以及主要内容之外的一些其他数据,这些噪声会对将来的数据文本分析产生干扰,所以要在数据清洗的第一个阶段清理干净,只保留网页中的主要内容的纯文本信息。数据清洗的另一项主要任务是将内容文本中的标点符号、停顿词等没有意义的词汇和标点去除,以提高教学资源库在运行时统计结果的准确性。数据清洗过程中较常使用的工具有Python、R、Microsoft word、Microsoft excel、Openrefine等软件,这些软件在功能上都能满足数据清洗的需要,综合比较各软件的功能、学习的难易程度、操作的便捷程度等因素,推荐使用Openrefine软件来进行数据清洗工作。Openrefine软件是由原Googlerefine软件继承而来的一款基于java语言的开源软件,该软件功能强大、体积小、简单易学,能满足绝大多数的数据清洗工作。尤其是该软件支持正则表达式和内置大量函数,对处理文本数据具有非常大的优势。
(二)数据存储
在数据存储方面,可采取两种选项:一种是将经过数据清洗后的文本独立存储到文件夹下,每篇文章一个文档,在使用时运用Python软件nltk语料库模块进行数据的读取和分析,该方法的优点是简便快捷,节省了大量的时间,语料存储成txt文档,可以很方便的进行查看,缺点是需要掌握nltk语料库模块或其他语料库软件的使用方法,在利用文本的过程中也需要付出一定时间的学习。数据存储的第二种选项是利用文本挖掘软件将清洗后的网络文本转换成文档-词项矩阵(DMT)的形式进行存储,该矩阵中每一行代表一个文档,每一列代表一个词项,可以将文档存入到Redis、Mangodb等关系型数据库或本地硬盘中,优点是提取将文本归类并进行了初步处理,使用时只需调用文档即可进行分析。以上两种方式都是来进行数据的存储,具体采用哪种方式可以根据不同的需求进行选择。
五、结论与展望
本文认为基于网络的多语种教学资源库必然会对区域国别学科的教学和研究产生重要的意义和变革,介绍了基于多语种网络自然语言文本的教学资源库相对于传统语料库的优势和不足,认为基于网络的自然语言文本库对语言研究和教学有着重要的推动和改革,并结合实际情况介绍了构建多语种资源语言教学资源库的基本原理、数据采集、数据清洗和存储的原理和方法,对现实应用有较全面的指导。未来,在基于网络自然语言资源库的数据采集效率、数据精确识别和分发版权方面,还要继续深入研究。
注释:
①夏立新,楚林,王忠义,等.基于网络文本挖掘的就业知识需求关系构建[J].图书情报知识,2016(001):94-100.
②魏顺平,何克抗.基于文本挖掘的领域本体半自动构建方法研究——以教学设计学科领域本体建设为例[J].开放教育研究,2008(05):95-101.
③王妍,王原,大学英语网络教学平台的设计[J].现代教育技术,2005(03):45-48.
④高利明.教育技术对教育改革的支持作用[J].开放教育研究,1997(02):19-22+49.