(阜新高等专科学校,辽宁 阜新 123000)
1 引 言
数字化技术的发展和智能设备的应用使图书馆的数据也呈现出大数据的“4V”特征,即大量(Volume)、多样(Variety)、高速(Velocity)、价值(Value),其中,读者数据(如到馆、图书外借、电子资源下载与浏览、空间利用、访问日志等)的动态特征最为明显,呈指数型增长,高校图书馆也开始重新审视这部分数据所能创造的价值与服务升级,如何发现并利用这些数据的深层价值,推动服务的快速更新迭代,让图书馆的服务更懂读者,更能精准服务于读者,正是当前图书馆界关注的焦点。重庆大学图书馆以数据为中心重新设计图书馆的智慧服务架构,不断提升数据管理与数据服务的能力,在该校图书馆主页的“猜你喜欢”、学院数字图书馆、课程文献中心等模块为读者学习提供了精准的支持。南京大学图书馆成立智慧图书馆研发与测评中心,不断推进数据融合与智慧服务,全面构造基于数据的智慧服务新生态,于2019年4月26日发布新一代图书馆服务平台NLSP(Nanjing University Library Services Platforms)。此外,北京大学、深圳大学、宁波大学等高校的图书馆也在积极探索并推进新一代图书馆服务平台的建设,也都把数据作为重要的支撑点和发力点来驱动服务创新。本文以我国部分高校图书馆的数据服务案例为研究对象,详细梳理数据研究与利用的现状、特点及趋势等,在此基础上构建数据服务框架,全面感知读者数据,根据不同层级读者的需求特征,从数据消费者到价值贡献者,为读者提供分众化、个性化的阅读推广服务,在阅读推广常态化的大环境下,以数据视角诠释如何提升阅读推广工作的价值贡献力。2 高校图书馆数据研究与利用现状
2.1 北京大学图书馆发布年度阅读报告
北京大学图书馆从2006年开始发布阅读报告,是国内最早发布年度阅读报告的高校图书馆。该报告认真梳理了北京大学图书馆与读者之间的关系,将数据划分为空间数据、资源数据和活动数据,主要从整体概况、读者到馆量与主页访问量、资源检索与利用、读者借书及特征、阅读设备与阅读活动等五个维度具体呈现,力求数据的完整;在方案实施方面,跨平台建立基础数据池,对数据进行清洗、去噪,建立数据关系,借助可视化技术展现结论;在创新应用方面,主要从检视馆藏布局与服务方式的有效性、发现资源利用趋势及特征差异、总结资源利用规律并优化配置、发掘热门资源并促进深度阅读等方面来推动数据价值的落地,真正做到让数据来推动服务的优化与升级。2.2 重庆大学图书馆打造智慧图书馆
重庆大学图书馆与维普资讯从2016年开始合作,联合打造新一代资源服务门户,通过全面整合资源数据、运行数据,构建面向学科、面向读者、面向场景的智慧图书馆服务平台,于2016年12月16日正式启用。智慧图书馆服务平台实现了纸质资源、电子资源的元数据收割与高效管理,并以读者运行数据的分析利用为驱动,打通了资源层、数据层和用户层之间的交互通道,最终面向读者提供基于需求导向的教学课程资料库、科研专题资料库、学院数字图书馆、个人资源库等智慧化产品,为高校图书馆探索智慧化服务提供了宝贵的实践经验。2017年底,重庆大学图书馆又与京东阅读合作,深度挖掘电子书的阅读特征,不再简单地以“借”的数据来考量读者的阅读情况,而是更多地关注“读”的数据,例如,每一本书的阅读进度、阅读时长、阅读时段以及所有外借图书的类别特征、阅读率等,这些更为精细化的阅读数据为图书馆开展智慧服务提供了更有价值的数据支撑。2.3 南京大学图书馆开发新一代图书馆智慧服务平台
南京大学图书馆依托超星公司的技术优势,联合开发了基于云部署、微服务架构、纸电融合的新一代图书馆智慧服务平台,于2019年4月26日发布。该平台以纸质资源管理系统、电子资源管理系统和资源发现服务的多维组合、按需定制为基础,推动多层级服务、数据相互关联的统一部署,打破以往各系统孤立运行的模式,实现资源与服务的智慧融合。新一代图书馆智慧服务平台集成了中央知识库、采选平台、馆员智慧服务平台、读者应用服务平台四大模块,强化数据驱动下的技术融合与快速迭代,并以数据融合为支撑在平台管理深度与开放互联广度上不断突破创新,最终在AI智能服务、VR沉浸式服务、机器辅助服务、空间场景服务等方面满足读者的智慧需求。3 数据服务框架构建及价值贡献力提升路径
3.1 数据服务框架构建
随着阅读推广工作的常态化开展,阅读推广不应过多注重形式的创新,而应更加关注内容的匹配性、价值性、系统性,因此,图书馆需要通过数据来驱动阅读推广价值贡献力的提升。通过前面的案例分析发现,我国部分高校图书馆已开始关注到数据的价值,并通过数据中心及平台建设等方式应用数据,但目前处于初期探索阶段。综合以上案例,笔者将数据服务框架分为数据生产层、数据分析层和数据应用层三部分(见图1)。数据生产层主要是对图书馆的资源数据、读者数据和运行数据进行再组织的过程,以使输出的数据能被分析层接受,具体包括清洗、校验、加工、抽取、存储、备份等环节;数据分析层主要是围绕对数据生产层传递过来的数据在阅读推广层面可能产生的创新驱动能力进行精细化分析,包括到馆人次、借阅册次、电子资源下载、读者活动、空间利用、科研等层面数据的特征分析,而不再仅仅是简单的到馆人次、借阅册次等数据搜集;数据应用层主要是根据分析层的数据特征和不同读者群体的特征,推进阅读推广工作的分众化、智慧化,重构阅读推广的价值贡献力和导向效应。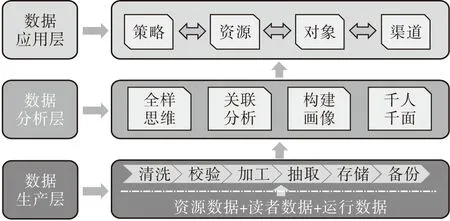
图1 数据服务框架
3.1.1 数据生产层。图书馆的数据可以分为资源数据、读者数据和运行数据,数据生产层需要将这三类数据进行融合、组织、输出。资源数据包括馆藏纸质资源、电子资源、自建特色数据库、机构知识库等,在资源数字化的基础上,要不断细化资源粒度,例如,纸质图书从整本揭示到章节、段落甚至句子的有序碎片化揭示,是因为单纯以文献为单元的知识组织方式已经无法满足读者对信息的精细化需求,只有通过知识元的重构才能为读者提供更有价值的资源信息,缩短读者的等待时间、阅读时间。读者数据能够帮助图书馆快速识别读者的基本特征,通常包括所在学院、专业、研究方向、课题、科研成果、兴趣、关注领域等属性,这类数据不完全局限于图书馆的自动化系统,如果具备条件,尽可能地与高校教务处、学生处、研究生处、科研处等部门的业务系统进行数据共享,以便形成相对全面、多维的读者数据体系。运行数据指读者在利用图书馆过程中产生的各种动态变化数据,包括到馆人次、借阅册次、电子资源下载、读者活动、空间利用、科研等数据,这类数据在构建读者画像及数据分析层中将发挥重要作用,因此要保证数据属性的完整与有效。
3.1.2 数据分析层。数据分析层主要是对数据生产层传输过来的数据,通过全样思维、关联分析、构建画像、千人千面等技术或方法,围绕其在阅读推广层可能产生的创新驱动能力进行精细化分析,而资源数据主要用于与分析结果进行匹配化推广,因此,这里主要介绍读者数据、运行数据的关注属性及分析维度(见表1)。对读者数据的分析应根据教师读者和学生读者不同身份的属性特征进行不同维度的静态画像描述,如教师读者侧重于研究方向、课题及科研成果信息等,学生读者侧重于学院、专业、兴趣及关注领域等,据此分析结果在应用层向读者推送常态化阅读服务;对到馆数据应重点关注读者到馆、离馆人次的时间特征及在馆时长等;对借阅数据的分析应重点关注图书借阅的主题特征、借阅时段规律、借阅周期反映出的阅读深度特征等;对电子资源下载数据的分析应重点关注文献下载的主题特征、时段特征及需求量等;对读者活动数据的分析应重点关注读者参与时段呈现的规律、活动主题特征及参与人数等;对读者空间及座位利用数据的分析应重点关注空间预约时段规律、使用方向特征及座位预约时段规律、座位使用密度分布等;对科研数据的分析应重点关注成果的学科分布、主题特征,成果发表时间规律、刊物等级分布,成果类型、数量等。通过这些数据的特征性、规律性分析,可以在应用层向读者提供更有价值的服务,例如,根据座位使用密度进行馆内阅读信息发布,在人流密度较高区域放置实体阅读图书推广专架,根据读者到馆时段规律,在人流高峰时段开展阅读推广微活动,这些都可以增加资源的阅读率和曝光度,让阅读推广工作更有价值。
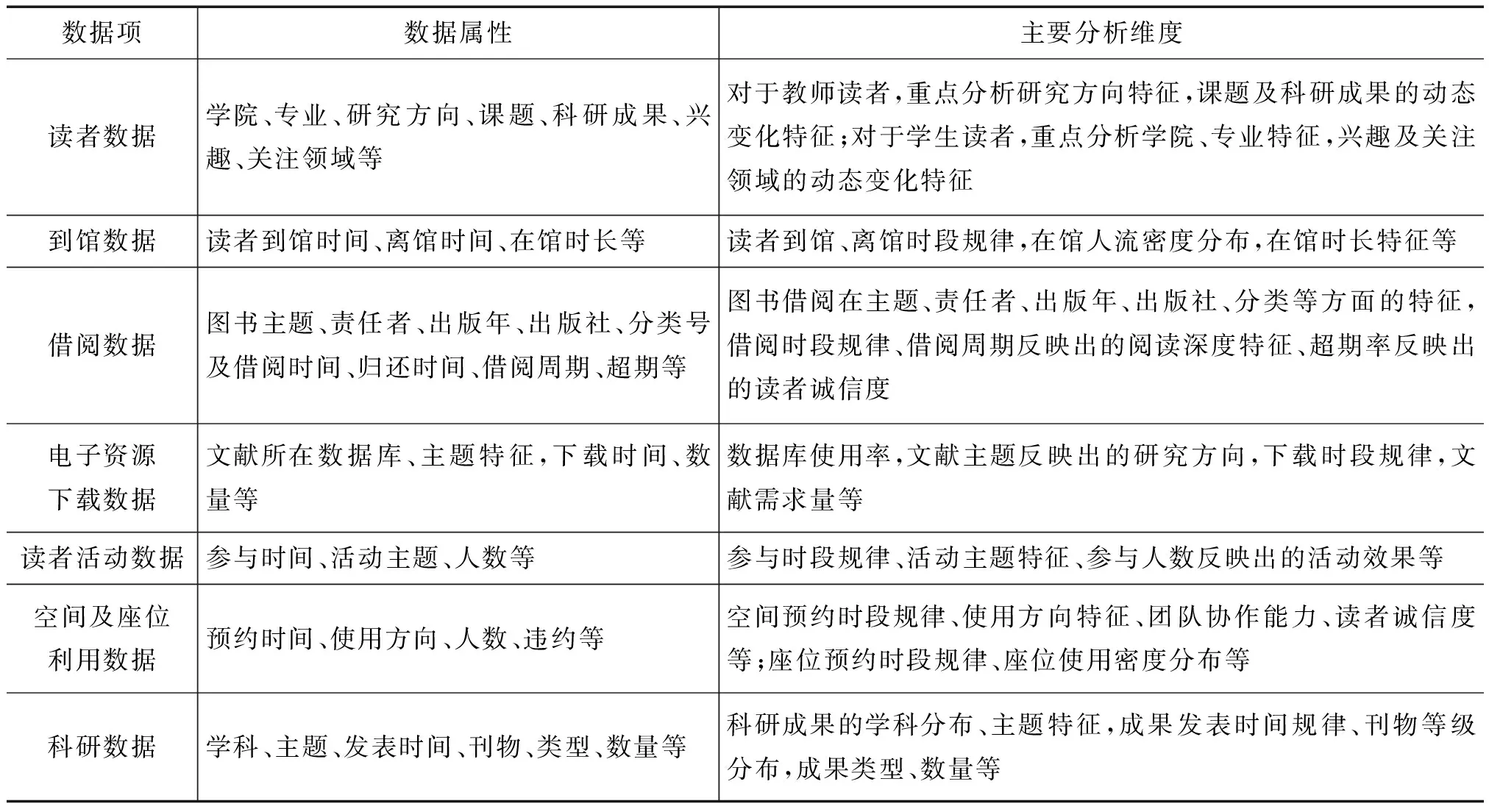
表1 数据分析方法
3.1.3 数据应用层。数据应用层是数据分析结果在阅读推广工作方面的具体实践,让阅读推广工作能够真正帮助到读者,产生价值和效益。在策略方面,以数据分析层的结果为依据,根据读者特征向其推送具有个性化需求的阅读服务,而不是简单的宽口径、大众化服务,同时,满足读者定制阅读需求,通过反馈、评价、互动等机制不断优化阅读服务策略;在资源方面,通过资源粒度的细化和知识元的重构,向读者推送重新组织后的资源,缩短其从过量资源中获取目标信息的时间;在对象方面,在根据高校图书馆读者身份属性将读者群体分为教师读者和学生读者基础上,还可以根据所在学院、专业、科研、课题等对读者进行二次分层,对不同读者群体开展不同形式、内容差异化甚至千人千面的阅读推广服务,为不同读者个体创造个性化的阅读推广服务;在渠道方面,分为线上和线下两种形式,线上以微信、微博、官方网站主页等为阅读服务主渠道,随着读者向社交媒体的分流,还可以开通抖音短视频、今日头条、知乎、豆瓣等社交新媒体的官方服务号,拉近与读者之间的距离,线下服务要结合读者的密度分布、流动趋势、时段规律等特征投放阅读资源,例如,在人流密度较高的阅览区域设立阅读推广专题书架等。
3.2 数据价值贡献力提升路径
根据数据服务框架功能界定及数据生产层、分析和应用层的主要任务和功能,在阅读推广数据价值贡献力提升的路径中,主要围绕以下四个方面推进:3.2.1 资源粒度精细化。资源粒度精细化主要从三个方面推动资源数据化进程,为阅读推广数据化驱动在资源层面打好“地基”:一是深化纸质资源的数字化揭示。在现行版权框架下,难以对馆藏纸质资源进行全文数字化加工,只能通过对内容的深度揭示进行粒度细化,例如,对某一本图书的揭示除了依托OPAC系统通过题名、责任者、主题词等揭示,还要把图书的目录、章节、书评等内容进行数字化揭示,以便实现更加精准的检索与匹配。重庆大学图书馆已经在其使用的弘深搜索中加入了纸质图书的摘要项,对图书内容进行详细介绍,如果能扩展到章节、目录等并提供检索服务,将会大幅提升图书与读者之间的契合度;二是电子资源的元数据整合。需要考虑统一的数据建模与编码方式,并在下一代图书馆服务平台理论指导与实践驱动下,推动跨类型的数据流通和知识的再组织与再融合,与数据库商协作,加速数据本地化的部署与服务。三是自建资源库的共建共享。与教学单位协作,对未公开发表的原生资源(讲义、教案、课件、实验数据等)通过多点采集、分布建库、授权使用等流程推动本校原创智力成果的再开发与再利用。
3.2.2 读者群体分众化。构建不同层面的读者社群画像,可以从两个维度推进(见图2):一是根据高校读者静态属性分为教师读者群、学生读者群、社会读者群等。教师读者群可以按学科、课题、科研、年龄等进行再次分层;学生读者群可以按学院、专业、兴趣、关注领域等进行再次分层;社会读者群可以按年龄、学历等进行再次分层,层级越细,服务越精准;二是在静态属性分层基础上,结合高校读者动态特征对社群进行校正或再次分层。这主要依托读者的行为数据完成,包括到馆人次、借阅册次、科研、读者活动、空间及座位利用、电子资源下载等数据,且对这些数据的分析不是简单地关注“次数”“册次”等,而是要关联分析、挖掘特征。例如,对某一高校读者的借阅数据分析,可以通过借阅周期判定阅读深度,文学类图书一般3—7天为有效阅读,非文学类图书一般7天以上为有效阅读,对于电子书则可以通过阅读器来准确获知阅读情况,阅读率在80%以上为有效阅读,从而能够准确分析读者的阅读特征。例如,重庆大学图书馆通过与京东阅读合作,能够准确掌握读者对每本电子书的阅读情况(阅读深度、阅读时间、阅读周期等),从而分析读者的阅读喜好,进而推送相关资源,在读者动态特征获取方面可以与网络中心合作,获取读者网络浏览cookie,在保障隐私的前提下,分析读者关注社会信息的特征,以此作为一个参照维度,向读者推送相应的校内资源,类似于今日头条、淘宝等网站的相关信息推送策略。
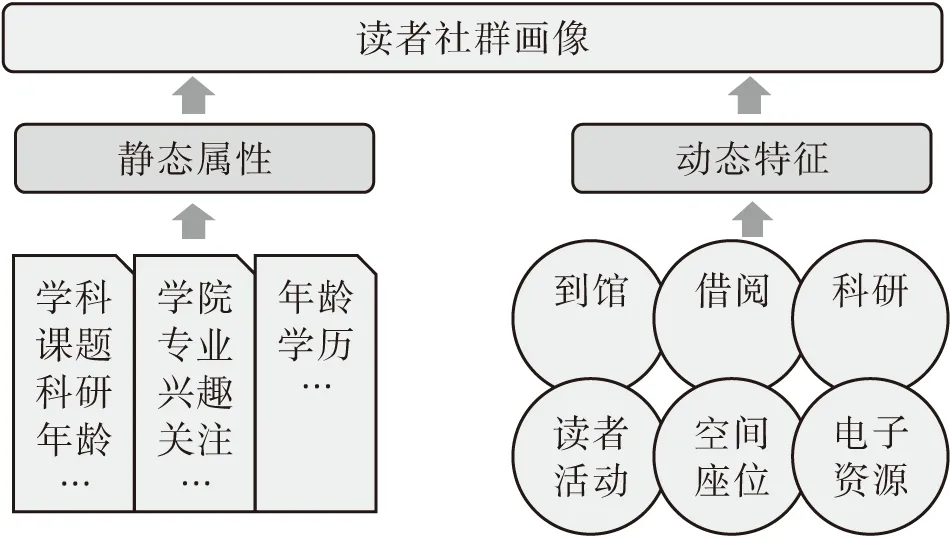
图2 读者社群画像构造
3.2.3 推广渠道移动化。阅读推广渠道主要包括线下阅读空间、传统媒体和新媒体。线下阅读空间的主要受众群体为经常活动在图书馆的读者,图书馆以空间为载体为他们提供线下阅读推广活动,如沈阳师范大学图书馆历时3年精心打造了5大类22个主题阅读空间,以空间为阵地,联合本校各学院开展主题阅读、经典阅读、绘本阅读、影音阅读等特色阅读活动,发挥空间优势与能动作用。传统媒体主要包括网站、电台、电视台、报纸等,适用于推广体量较大的内容,读者需要有充足的时间来阅读推广内容。新媒体,通常有微信、微博、抖音短视频等,相对于前两种推广渠道,新媒体具有移动化、多元化、个性化等特点,迅速成为读者的流量高地,高校图书馆应该充分利用新媒体介入读者社群,为其提供全新的阅读推广服务。通过调查发现,中国国家图书馆、上海图书馆、河南工业大学图书馆、内蒙古农业大学图书馆等在抖音短视频平台率先开设官方服务号,发布的内容以讲座、活动介绍、服务宣传等为主,这些新颖、活泼的服务方式引起了读者的高度关注,在提高图书馆在读者社群的曝光度的同时也充分利用了读者的碎片化时间推进阅读推广,点击率较高,效果较好;武汉大学、吉林大学珠海学院等在微信平台开设了官方视频号,高校图书馆也可以借鉴。在数据时代,依托新媒体搜集读者关注的领域与阅读喜好,可以帮助图书馆实现个性化的点式推送,突破媒体边界,让阅读推广深深扎根于读者社群中。
3.2.4 评价机制多元化。多元化评价可以从主体跟踪、客体反馈两个层面展开:一是主体跟踪。图书馆作为阅读推广的实施主体,在开展阅读推广的同时应更加注重效果的跟踪与评价,避免主观推测,而是以开展阅读推广之后产生的一系列阅读数据作为依据。例如,对某一场读书分享会的效果进行评价,在活动之后可以围绕相关图书(主题相关、作者相关等)的借阅数据(借阅次数、阅读时长等)、相关资源(论文)的下载数据等进行深度分析,挖掘趋势与规律特征,如图书热度不单纯以借阅次数为评价标准,还应结合借阅时长,以准确评价阅读的有效深度,这样真实的数据才能对阅读推广效果进行有效评价。二是客体反馈。每项阅读推广活动结束后都可以增加简短的反馈单元,与读者建立互动通道,接受读者的反馈,客体反馈能够比主动跟踪更能准确感知服务的价值贡献度。反馈单元在内容设计上要讲究实用性,而非形式化,杜绝“非此即彼”的评价模式,如对某本书的评价不是简单的“有用”或“没用”,而以分值形式(从1-10打分)评价,这样更能准确地捕获读者的价值反馈,而这些价值反馈在评价机制中也更有参考价值。
4 数据服务框架及价值贡献力提升预期效果
在资源组织层面,通过不断细化粒度,在进行推广时既能保证资源的覆盖面,又能降低读者的阅读难度,让不喜欢读书的人开始喜欢读书、让不会读书的人开始高效读书,引领读者走进阅读、深入阅读,而不是将所有资源全盘扔给读者,让读者自行筛选。在推广对象层面,以数据为驱动,在保证读者隐私安全的前提下,根据读者静态属性、动态特征等建立不同层面的读者社群画像,提供分众化的阅读推广服务,帮助读者重建专注化的阅读能力、培养读者的阅读兴趣、降低读者获取有效知识的难度、打造系统化的知识体系,避免给读者造成更大的阅读压力,从而提高推广内容的受用度。
在推广途径层面,依托传统媒体、线下空间进行阅读推广的同时,应该顺势而为,有效借助新媒体的力量推动阅读推广渠道的多元化发展,促进阅读内容的生产与交换,为不同层级读者打造有温度、有活力的阅读圈。
在效果评价层面,依托阅读数据对阅读推广效果的多元化、全景化进行评价,可以进一步准确修正阅读推广的策略体系(包括制度、规划、内容、形式、途径等),使阅读推广更懂读者,进而让阅读推广产生更大的价值贡献力,而不能让阅读推广沦为展示行政业绩的工具,只注重规模,不注重效果。
5 总 结
数据正在加速各行业的颠覆性变革,图书馆的发展也开始趋向智慧化,同样,阅读推广服务要以数据为驱动以体现其价值性,为此,我们要以数据思维来重构阅读推广环境,从资源、途径、方法等层面推动服务场景与服务能力的升级。