(山西医科大学 a.图书馆;b.管理学院,山西 晋中 030619)
1 图书馆智慧服务现状
随着信息技术的不断发展,图书馆正在从封闭、机械的服务方式向开放、智慧的服务方式转变,如何存储海量数据、如何从海量数据中挖掘出有价值的信息、如何培养出高水平的图书馆员是实现图书馆智慧服务的重点。2003年,芬兰学者Aittola M提出“智慧图书馆”的概念,随即成为图书馆的研究热点。武汉大学信息资源研究中心陈远等提出,智慧服务包括智慧性技术服务和智慧性知识服务。智慧性技术服务是指通过使用智慧化设备帮助读者实现知识的“易知易用”。例如Kiril Antevski等提出一种基于低功耗蓝牙和Wi-Fi的混合定位系统,用户通过该系统在智慧图书馆中按照兴趣创建学习群,在该群内与兴趣相同的人进行学习和讨论。智慧性知识服务指通过对图书馆海量数据进行挖掘,最大限度地开发其价值,为图书馆智慧性知识服务提供建议。例如青岛大学陈淑英等采用关联规则数据挖掘技术对不同专业用户群4年图书借阅数据进行分析,为图书馆提供有针对性的图书推荐方法,提升图书馆智慧性知识服务能力。江苏理工学院柳益君等提出图书馆智慧服务需求表现在四个方面:1)知识零空间共享,让隐性知识显性化,让知识的传播没有障碍;2)个性化推荐,根据用户需求,为用户提供更有针对性的知识服务;3)知识导航,将知识按主题划分模块,为用户提供不同主题的知识模块;4)图书馆业务优化,优化图书馆馆藏、采购质量、人员配备、信息安全等,并根据用户需求安排阅读推广、讲座等不同主题的活动。目前,国内图书馆智慧服务研究主要集中于智慧服务模式、发展策略和技术实践这三个方面,其中关于技术实践研究的论文较少。鉴于此,本文基于图书馆智慧服务需求提出基于Hadoop的图书馆智慧服务体系,探讨图书馆智慧知识服务,为图书馆采用大数据挖掘算法和技术实现智慧化知识服务提供参考。2 基于数据挖掘的图书馆智慧服务体系
2.1 基于Hadoop的技术支撑体系
随着互联网技术的快速发展,图书馆产生巨大的数据量,海量数据的挖掘成为图书馆实现智慧服务的关键问题。Hadoop是Apache开源组织的一个分布式计算开源框架,具有跨数据源分析、离线计算、对数据进行二次加工等优点,Hadoop HDFS具备动态扩容和冗余化存储的能力,满足图书馆数据挖掘的需求。故本文构建了基于Hadoop的图书馆大数据挖掘技术支撑体系,以支持图书馆的智慧服务,如图1所示。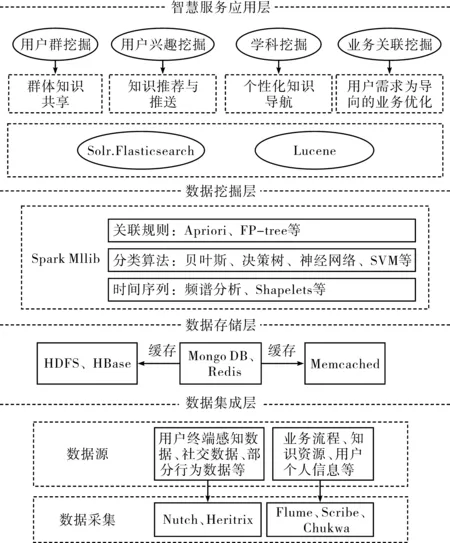
图1 基于Hadoop的技术支撑体系
2.2 数据集成和存储
2.2.1 用户数据。用户数据包括:1)显性行为数据,如读者借阅数据、下载、收藏、打分等;2)隐性行为数据,如读者浏览记录、点击量等;3)个人信息数据,如性别、年龄、专业等;4)社交数据,如论坛、微博、微信等;5)终端感知数据,如位置、时间、设备参数等。2.2.2 知识资源。知识资源数据包括书目库、专利库、中外期刊文献、电子资源等。
2.2.3 业务流程。业务流程数据包括各类咨询、检索查新、资源采购、馆际互借、文献传递、门禁、选座系统等。
用户数据中的社交数据、终端感知数据、部分行为数据等属于外部数据,需要通过爬虫技术从互联网上采集,如Nutch、Heritrix等。知识资源、业务流程、读者个人信息等属于馆内数据,可通过Cloudera的Flume系统、Facebook的Scribe系统、Apache的Chukwa系统等进行采集,以供后续数据分析使用。Flume系统设计架构巧妙,提供了丰富的agent和collector,用户几乎不必进行任何额外开发即可使用。Scribe系统设计简单,易于使用,但容错和负载均衡方面不够好。Chukwa系统属于Hadoop系列产品,直接支持Hadoop,但版本更新较快。
Hadoop的HDFS具备动态扩容和存储多份数据的能力,是大数据存储中最主流的解决方法之一,一般用于存储处理要求不高的数据,例如图书情报界全年关于智慧服务的论文。MongoDB适用于实时的插入、更新与查询的场景,例如读者社交信息、读者查询记录等。HBase适用于海量数据的存储和高并发查询的场景,例如图书馆电子资源访问日志。Memcached和Redis为关系型数据库提供了缓存机制,提升了系统响应速度。
2.3 数据挖掘算法
数据挖掘可以从海量数据中最大限度地挖掘出有价值的信息,为图书馆智慧服务提供依据。面对海量数据传统的数据分析模型已经无法应付,基于Hadoop的MapReduce框架提供了解决方案,并得到充足的发展。然而,相较传统Hadoop MapReduce框架法,SparkMLlib在运行速度、易用性、通用性及容错性上都有更好的表现,拥有更高更快更强的计算速度。故在数据挖掘层采用SparkMLlib机器学习库,包括关联规则、分类、时间序列等50多种常见的分布式模型训练算法。2.3.1 关联规则算法。关联规则挖掘是数据挖掘重要算法之一,其目的是分析和预测项目间的关联强度。迄今为止,有很多高效的关联规则算法被提出,其中最重要的是美国学者R.Agrawal于1993年提出的Apriori算法,以及J.Han等人于2000年提出的FP-tree算法。在图书馆智慧服务中,关联规则算法使用范围广、频率高,主要用于挖掘读者借阅记录和借阅日志建立分析模型,根据分析结果向读者推荐强关联图书,实现图书馆智慧服务,同时还可根据分析结果调整馆藏布局,减少读者找书的时间。北华大学李欣提出在图书馆集成管理系统的基础上采用强关联规则挖掘技术实现图书精准查询和个性化推荐功能。
2.3.2 分类算法。分类算法的目的是将图书馆读者群体按照专业、性别、年龄等因素进行分类,找出各群体的特征、群体间的关联、识别特殊群体等。根据群体特征图书馆可提供有针对性的服务,从而提高图书馆的服务质量,实现图书馆智慧化服务。常见的分类算法有贝叶斯分类、决策树分类、神经网络、SVM等。电子科技大学图书馆员彭莹采用C5.0决策树对读者借阅数据进行分析,建立读者借阅频度决策树分类模型,根据分析结果对图书馆的流通规则和采购策略提出优化建议。
2.3.3 时间序列算法。时间序列研究的是该数列随时间发展变化的规律,主要用于研究图书馆读者、资源的流通规律,建立分析预测模型,预测未来某段时间图书馆的情况,为图书馆开展服务活动、人员安排等方面提供支持。宁夏师范学院王建对宁夏师范学院图书馆2011—2016年图书资源相关数据进行短期预测分析,建立季节指数平滑模型,通过实验证明模型检验效能较好。
2.4 智慧服务应用
在图1的智慧服务应用层中,Lucene是Apache支持和提供的一个开源的全文搜索引擎工具包,提供了完整的查询引擎和索引引擎。Slor和Elasticsearch则是两个基于Lucene的、有着丰富的查询语言的全文搜索服务器,为检索、推送、知识导航、知识问答等智慧服务应用提供了技术支持。基于数据挖掘的智慧服务应用主要体现在以下4个方面:1)用户群挖掘。用户社交数据包括科研成果、研究方向、学历、专业等个人信息,以及微信、QQ等社交数据,用户群挖掘是对用户社交数据采用关联规则、聚类、时间序列等挖掘方法分析出用户之间的关联,实现知识共享。2)用户兴趣挖掘。采用已有的数据挖掘技术对用户兴趣数据进行挖掘,分析用户需求,根据分析结果有针对性地向用户推荐各类资源,实现智慧性知识推荐。3)学科和领域知识挖掘。采用数据挖掘方法对文献、知识资源数据进行挖掘,实现自动知识导航。4)业务关联挖掘。业务数据包括用户咨询数据、科技查新数据、资源采购数据、流通数据、用户行为数据等,采用关联规则、聚类、时间序列等分析方法对业务数据进行挖掘,发现某时间段、某类用户与某种业务之间的关联,发现进馆人数与天气的关联,为图书馆开展服务活动、资源采购、人员安排等方面提供支持。3 基于数据挖掘的图书馆智慧知识服务探讨
建立符合自身机构特色的智慧知识服务引擎是图书馆智慧服务方式之一,目的是为用户提供有针对性的服务,提高图书馆知识资源的利用率。本文提出一种智慧知识服务引擎体系,如图2所示。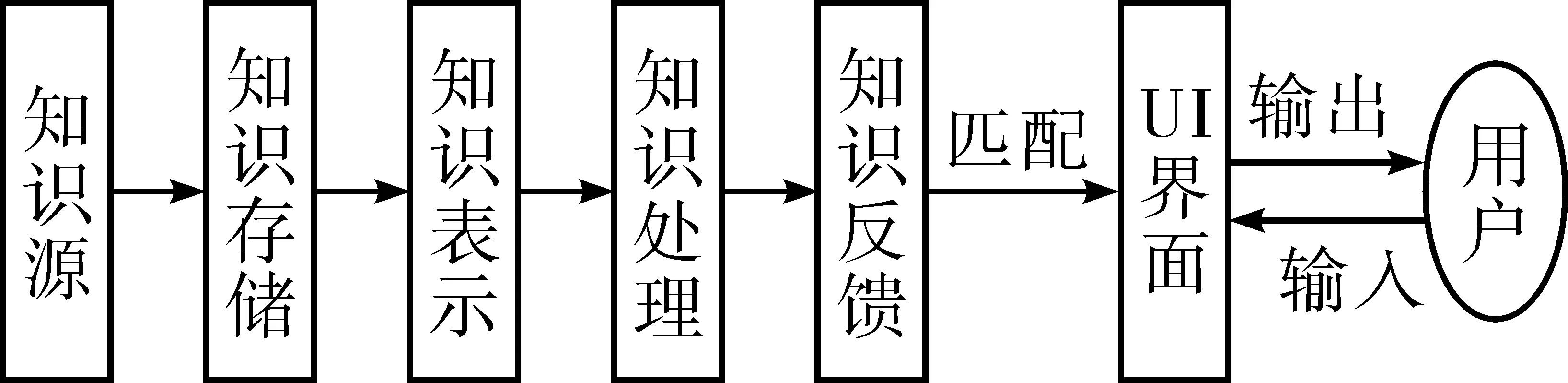
图2 智慧知识服务引擎框架图
智慧知识服务引擎包括知识源层、知识存储层、知识表示层、知识处理层和知识反馈层4个部分。第1层是知识源层,即图书馆数据来源,只要能够为用户提供智慧服务、满足用户知识需求的数据都可作为知识源,一般分为以下3类:1)馆内藏书、文献、电子数据库等静态知识源;2)RFID、读者借阅行为记录、图书馆电子设备记录数据等动态知识源;3)馆际互借数据、文献传递等馆外知识源。第2层是知识存储层,根据数据大小、类型、更新频率等特有性质将知识分层动态存储,方便随时调用。第3层是知识表示层,将知识进行统一标识,文章提出的引擎体系采用本体表示法,让隐性知识变为显性知识。第4层是知识处理层,主要包括以下3个处理过程:1)对数据进行预处理和简单的统计分析;2)根据数据特性采用相应的数据挖掘方法,建立知识分析模型库;3)对分析后的知识进行信度与效度检验,通过检验将其存入知识库中,并将知识库划为学科库、专题库、知识导航库、特色知识库等。第五层是知识反馈层,根据第四层建立的知识库建立索引库和倒排档,当用户输入服务请求后系统经过前四层的处理,最后在第五层的索引库和倒排档中进行知识匹配,并将匹配结果按照匹配度大小输出到交互界面。经过以上五层知识处理,用户在交互界面得到与请求相匹配的个性化检索结果,实现图书馆个性化智慧服务。
4 结 语
在“互联网+”背景下,信息技术不断发展,图书馆的数据量激增,应用数据挖掘技术实现图书馆的智慧服务是图书馆发展的必然趋势。基于Hadoop的技术支撑体系实现了图书馆数据的集成、存储、处理和应用,数据处理是核心环节,是实现图书馆知识共享、知识推荐、知识导航等智慧服务的关键技术,基于数据挖掘的图书馆智慧知识服务成为图书馆服务新模式。本文的研究为图书馆应用数据挖掘方法和技术实现图书馆智慧服务提供了参考,但仍存在一定的局限性和不足,未来可侧重于研究如何应用数据挖掘方法从海量图书馆数据中找到更有意义有价值的信息,从而使图书馆实现更精准的智慧化服务。