如果數據規模足够大,一定隱含着有待人們發現的各種規律和事實,大數據所能够發揮作用的範圍甚至會超出數據建設者自己的想象。這是大數據理念之所以得到廣泛重視的重要原因。中華民族五千年輝煌的歷史,積累了大量的世代相傳的燦爛文明,發明了傳承文明的系統符號——漢字。傳承文明的物質形式也從甲骨、青銅、竹簡、絹帛、紙張等發展到今天的數字媒體。幾千年來,人們主要是通過這些承載文明的物質形式瞭解歷史和認識歷史。數字媒體出現以前的介質形式在傳承文明過程中的作用無疑是巨大的,是任何人不能够抹殺的。由紙張製成的書是到目前爲止人類使用時間最長的記載文明的介質。漢文寫本是以紙張爲承載物質、以漢字爲符號體系的中華文明的一種承載形式。這種傳承文明的物質基礎,隨著人們的需求的提高,也在相應地改進。從歷史上看,這種改革所追求的最終目標是使記載文字的介質不斷輕便化。
但是從人類使用需求的角度講,文明的載體仍有很多需要改進的地方。這種改進不但要求實現介質的輕便化,更需要實現資訊獲取的快捷化。人們在這兩個方面都進行了不懈的努力。爲了追求介質的輕便,出現了現代意義上的書的形式;爲了追求資訊獲取的快捷,出現了圖書館、目録學,同時書的内容中也增加了目録和索引等。但是,書這種文明承載物的形式特質,決定了人們從中獲取資訊的方式主要是綫性的,也就是主要通過從頭到尾的閲讀,才能够獲得自己所需要的内容資訊。在數據庫出現以前,這種資訊獲取的方式一直持續了幾千年,而且仍然是當今的主流方式。儘管圖書館學和出版業已經非常發達,這種方式也没有得到實質性的改變。這種方式的主要弊端就是人們在獲取資訊時會浪費很多精力和時間,收效很少,效率低下。有一部歷史電視劇中曾經描寫了這樣一個情節,主人公曾經從一本書裏看到過治療某種病的方法,但是已經記不清是哪本書,也忘了具體是什麽辦法,恰巧此時,出現這種病的疫情,於是他就動員他的夫人幫他去找那本書,結果夫人花了十幾天時間、費了很大勁才找出來。雖然這是電視劇虚構的情節,但是相信歷史上這樣的事情很多很多。我們在開展自己的研究工作時,事先往往也需要花費很多時間和很大的精力去收集相關資料,實際上科研的相當一部分時間是浪費在資訊的收集和分析上。這種資訊的獲取辦法,嚴重阻礙了我們的科研效率。如果我們能够很快獲取我們需要的資料和資訊,將會大大縮短科學研究的週期。這種傳統的資訊獲取手段的低下效率,是傳統出版物的資訊傳播特性造成的。要改變這種情况就需要對資訊源(傳統出版物)和資訊的獲取途徑、方法進行改革。進入21世紀以後,這種改變已經悄然發生,很多傳統出版物已經變成結構化的數據存入電腦的數據庫中。資訊源的形態發生了巨大改變,由傳統的紙質出版物變成了結構化的電子數據。由於資訊源形態的根本改變,也導致資訊獲取手段從效率低下的綫性方式躍進爲超越時空、隨機、暫態實現的現代方式。人們可以在任何時間、從任何地方、暫態獲取指定的資訊。就現有的資源我們已經感受到這種新型資訊獲取手段的便捷和高效,實現這種變革的核心是新型資訊源——數據庫的建設。當然這種變革,還處於初級階段,主要原因是作爲新型資訊源的數據庫建設還只是剛剛起步,尤其是能够滿足這種變革的古代文獻的大型數據庫建設還没有真正展開。這正是我們開發日本漢文古寫本數據庫的動力、意義和學術價值之所在。
一、 古代文獻數據庫建設的種種嘗試
古代文獻如何從傳統的媒體形式結構化成爲能够高效利用的電子數據形式是當下需要探索的現實課題。實際上從20世紀90年代開始,就出現了一些古代文獻數位化的嘗試。1997年,濟南開發區匯文科技開發中心將《四庫全書》數位化,由武漢大學出版社出版發行。當時的數位化,只是將《四庫全書》原樣以圖像方式掃描進電腦,共200多萬頁,均以圖像格式存儲;《四庫全書》的目録資訊被録製成文本數據,並存入數據庫,以供讀者對書目進行檢索,方便利用。這是較早的以數字方式出版的古文獻。這種出版方式的優點是,電子圖像能够保存古典文獻幾乎所有的形態資訊,可爲今後古籍的整理提供幾乎與原始形態一樣的證據,但是和原始形態相比大大縮小了存放空間,同時還可爲進一步進行數據的結構化加工提供基礎。不足是,由於正文部分以圖像形態保存,不能够進行全文數據的結構化加工,因此不能够進行全文檢索等高級應用,利用時最多只能够按照目録進行綫性流覽。從讀者角度看,這種電子出版物只是存儲介質發生了改變,資訊的綫性傳播方式仍未改變。這是和當時的技術條件密切相關的,90年代的電腦技術水準,無論是數位化技術、還是計算存儲技術以及文字處理技術都無法和20多年後的今天相比。另外,古籍全文數據庫的建設還需要解決很多技術難題,比如能够容納古籍中所出現的所有文字符號的電腦代碼體系的建立。當時大陸電腦所使用的漢字代碼體系是GB2312,所能處理的漢字只有7 000種左右,再加上漢字的輸入技術也比較落後,因此建設大型古籍全文數據庫的技術條件並不具備。但是,出版物的電子化畢竟是歷史的潮流,實現資訊源的數據化和資訊獲取途徑的非綫性化是當代資訊革命的主要内容。特别是資訊獲取方式的非綫性化,可以打破有史以來一直保持的綫性流覽方式,大大提高資訊的獲取效率,是對人們閲讀方式的徹底革命,這是資訊技術發展到這一歷史階段人們在資訊獲取上的客觀需求。與此同時,由於出版印刷行業也發生了數位化革命,告别了鉛與火的傳統模式,迎來了電腦輕印刷的時代,出版環節也積累了許多和傳統出版物一致的電子數據。因此,真正意義上的電子出版物在90年代後期也開始陸續出現。如日本的《新潮文庫》(100册),就是這類出版物的典型代表。《新潮文庫》不是簡單地將原書以圖像方式掃描進電腦,而是將内容以數字文本形式録入,建成數據庫,然後用電腦軟體模仿傳統出版物的形式將内容呈現到電腦熒幕上。由於書的内容已經以文本數據形式建成了數據庫,因此,這種出版物是可以全文檢索的,實現了讀者的非綫性閲讀要求。
但是,上述兩種出版物雖然實現了資訊源的電子化,特别是《新潮文庫》電子版也實現了文本數據的數據庫存儲、可以全文檢索,但是由於只能够在個人電腦上使用,而且存儲介質體積仍然比較大,所以這一類電子出版物數據庫的使用仍然受限。近年來隨著以智能手機和電子書等爲代表的便携移動終端的普及、存儲介質容量的大幅提升、體積微型化,對電子出版物的需求將會越來越多。基於這種情况,現代圖書的綫上數據庫建設也如同雨後春筍一般。由於出版印刷行業大多電子化,因此,現代圖書的數據庫建設從技術上講是比較成熟的,所需要解決的是版權等其他問題。但是古代典籍數據庫的建設,無論從技術還是産品都没有現代出版物那麽成熟。儘管如此,國内外還是有很多單位在嘗試,也有一些産品已經投入了使用。
中華書局的《中華經典古籍庫》是目前國内已經投入使用的全文古籍經典數據庫,該數據庫收録已經整理出版的中國古籍1 900餘種,共計10億字左右。這個數據庫同時在Web和微信兩個平臺上發佈,檢索工具功能强大,其高級檢索功能可以從文章名、文章内容、書名、作者名、出版社等多個角度進行檢索。下圖爲該古籍庫的高級檢索介面和以“民主”爲關鍵字的檢索結果。
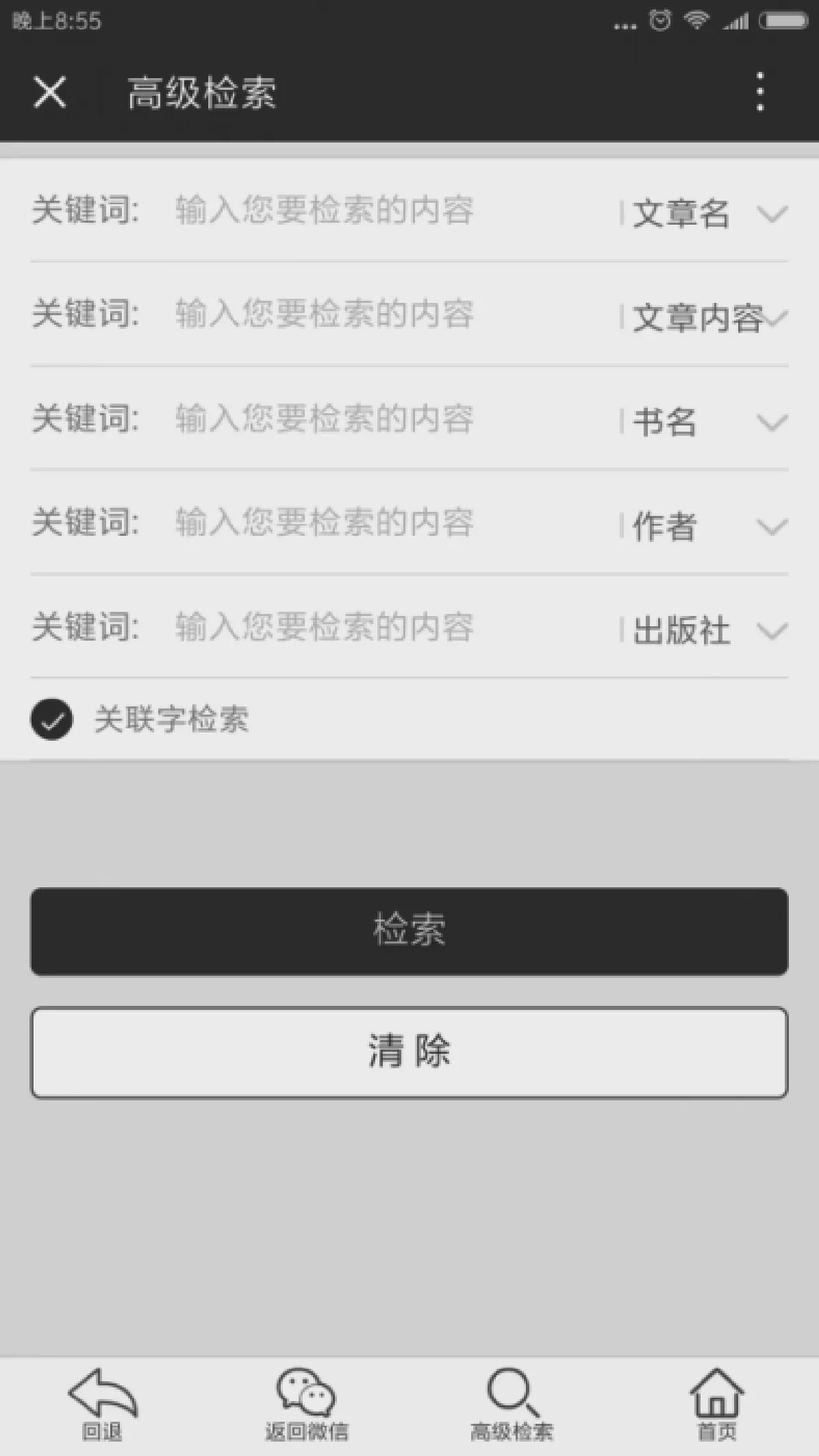

從一般讀者的角度看,這樣的功能和結果檢索呈現方式也許是可以滿足大多數情况的要求的。但是從古籍整理和利用古籍開展進一步研究的角度看,仍存在一些問題。
首先,檢索結果不够精確。古典文獻數據庫不僅只是文獻學研究的數據庫,它可以在歷史學、語言學、政治學、國際關係研究甚至會在數據庫開發者都無法預測的領域中發揮作用。這就要求檢索工具需要有强大的數據分析能力,但是《中華經典古籍庫》的檢索工具只提供了傳統的以字串爲對象的數據檢索方法,這使得檢索結果中混雜著很多不需要的雜質,有時命中結果的絶大多數是雜質,而我們真正需要的數據却被掩蓋在了這些雜質中。如語言學研究中,非常關注一個詞的詞滙化歷程,古籍數據庫對這種歷時語言學研究具有非常重要的價值。例如我們要考察現代意義上的“民主”一詞的詞滙化情况,我們以《中華經典古籍庫》爲歷時語料庫,以“民主”爲關鍵字進行檢索,該古籍庫檢索工具回饋了487條包含“民主”的結果。我們仔細分析這些“民主”發現,他們絶大多數並非是一個詞,而是“民+主”,成詞的“民主”却掩蓋在這些語言雜質之下,很難被發現,因此我們也就很難考察現代意義上的“民主”的成詞年代。《中華經典古籍庫》並未提供更進一步的數據檢索分析方法。其實,並非只是《中華經典古籍庫》的檢索工具存在這樣的缺陷,目前幾乎所有的古籍檢索工具都存在這樣的問題。

其次,檢索結果無法以與其對應的文獻原始面貌呈現。在古文獻整理過程中,文獻原始面貌的呈現非常重要。任何一本整理好的文獻,都不能説是完全正確,完全詮釋了原文獻的内容,總存在或多或少的值得進一步斟酌的地方。學者們在利用整理好的文獻開展進一步研究時,常常還需要同原始文獻進行對照分析。因此,在對命中内容的原始面貌的呈現對古典文獻數據庫的功能來講非常重要,尤其是對古文獻研究人員來講很重要。但是,目前的古文獻數據庫基本上只能提供所命中内容的文本數據,而且這些數據的顯示形式往往是雜亂無章的文字,很少能够把專家整理後的文獻狀態呈現出來,這些文本數據的原始樣子也看不到。《中華經典古籍庫》也没有克服這些弊端。上圖是用“民主”爲關鍵字從《中華經典古籍庫》中檢索到的“民主”的上下文情况。
從語言學研究的角度講,這樣的呈現結果是可用的,因爲語言學研究主要是摘抄例句,因爲回饋結果是文本形式,所以從中摘抄例句非常方便。但是,從文獻學角度講,如果這些整理過的内容本身存在值得斟酌的地方,那麽這樣的呈現方式是無法看到存在問題内容所對應的原始典籍的狀態的,甚至整理後的狀態也已經被丟失了。
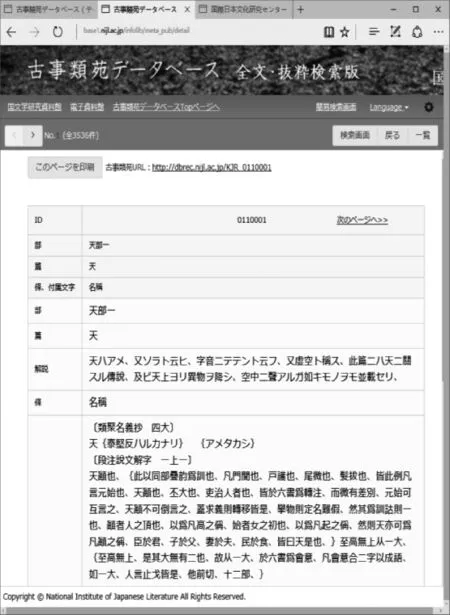
通觀目前的古籍數據庫,基本上都是這種情况。日本對漢文古籍的整理和數據庫建設情况也基本上和《中華經典古籍庫》的情况差不多。下面是日本“古事類苑”數據庫的全文檢索結果。
總的來講,目前的古籍數據庫建設可以分成兩大類,一類是以原始文獻的實體爲對象進行圖像數位化,而建設成的古文獻圖文數據庫,如上述武漢大學出版社出版的《四庫全書》電子版。這類數據庫的優點就是能够保存典籍的原始面貌,缺點是不能够進行全文檢索,很難在更寬泛的領域發揮作用。第二類是對整理後的古籍數據進行加工而建設成的全文數據庫。這一類數據庫的優點是能够進行全文檢索,可以在更多領域得到應用。但是目前這類數據庫在檢索工具的數據分析能力和原始文獻面貌的呈現方面還没有達到應有的水準。將來古籍數據庫建設的目標,應該是第一類和第二類的結合體,就是將第一類的典籍圖文數據融入到第二類的全文數據庫中,開發更加智能化的檢索手段,將命中數據以文獻的實體狀態呈現。

二、 古典數據庫建設的難點和我們的實踐
我國保存有大量的古典文獻,加上散失在世界各地的漢文古典文獻,漢文古籍的數量非常龐大,如果能够將這些典籍用數據庫進行管理,並對其數據進行智能化的分析利用,其社會效益將是無法估量的。但是古籍全文數據庫的建設比現代書籍全文數據庫的建設要困難得多。首先古代典籍没有現成的數據可以利用。現代出版物,尤其20世紀90年代以後出版的書籍,在出版環節都已經電子化,數據都是可結構化的電子文本,有的即便没有電子數據,但是由於現代出版物使用的文字是規範化的漢字,可以使用OCR技術進行電子化。但是,古代典籍却没有這樣的便利。大多數古籍由於時代久遠,其實體已經面目全非,要對其全文數據進行結構化處理,必須對古籍進行整理和校注,這本身就是一個浩瀚的工程。因此古代典籍一般没有現成的、可利用的電子數據,大多需要重新録入。由於古代典籍都是寫本和刻本,由於時間久遠,而且所使用的文字很不規範,充斥著俗字、異體字,出現很多難以辨認的情况、同時内容散逸的情况也比比皆是,因此必須由專家進行辨認整理、輸入,手工輸入數據這一環節是很難跨越的。
其次,典籍中出現的字元,字形複雜不統一,種類繁多,有的甚至難以辨認,這對現有電腦代碼體系提出了挑戰。目前電腦代碼體系雖然比90年時完善了很多,有“萬國代碼”之稱的UTF-8代碼體系幾乎收録了世界上現有語言的所有現行文字。但是即便如此,用漢字書寫的古代典籍中的許多俗字、異體字仍然没有收録。而且典籍中的漢字非常不規範,有的甚至古文獻專家也很難識别,這部分字元的處理非常困難。實際上古籍中的很多漢字現在已經不使用了,因此電腦代碼體系無論多麽完善,也不可能將這些漢字全部收録。古寫本中的漢字情况更加複雜,因此,古寫本數據庫建設的第一難題應該是古代漢字的整理和資訊化處理。
檢索結果内容的格式還原以及與其對應的原始狀態的呈現比較困難。任何專家對典籍的理解都會存在一定的局限性,因此每一個人對典籍的校注也都不可能十全十美,都會存在一些有争議的地方。典籍全文數據庫就是要提供一個方便的辦法,使人們在前人工作的基礎上,不斷加深對典籍的認識,從而使校注工作能够還原或者更加接近祖先的原意,最終使典籍的整理校注工作走向完善。這就需要將指定内容的前人工作情况以及典籍的原始情况還原出來。典籍的形態比較複雜,對典籍的形態和内容進行全方位結構化,並能够檢索已達到重複利用的目的,這是非常困難的。整理後的典籍,爲了保持原始形態,在數位化時需要使用複雜的格式化手段。但是,全文檢索時暫時只能針對文本數據,因此存在如何將檢索到的文本數據資訊恢復到與原始文本對應的形態,就目前的技術水準來講這也是一項非常複雜的工作。
古文獻全文數據智能化檢索。古代漢語和現代漢語存在結構化差别,現代漢語通常以2字詞爲主要的語言單位。在電腦自然語言處理技術的開發方面,面向現代漢語的電腦智能處理技術也有了長足的進步,現代漢語的分詞標注等技術也非常成熟。這些技術應用在現代漢語的資訊抽取方面不但能够大大提高資訊提取的效率,而且抽取結果的精確率也能够大幅度提高。而古代漢語是以字爲詞,字和詞基本上是統一的。這種差别反映在數據庫的檢索上,古代漢語和現代漢語相比更加複雜。由於古代漢語一個字往往就是一個詞,而且,針對古代漢語的電腦資訊處理技術非常滯後,目前幾乎没有什麽可用的、處理古代漢語的技術。因此,檢索古漢語詞時我們所能提供給檢索工具的資訊很少,通常只有一個字,這樣回饋的結果中雜質非常多。
古文典籍數據的結構化和數據庫建設所面臨的這些困難,不是一朝一夕能够解決的,需要電腦專家和古籍整理專家長期不懈的共同努力。在這些困難徹底解決之前,我們在建設日本漢文古寫本數據庫時,將儘量考慮彌補目前古典文獻全文數據庫建設中的不足。我們主要提出了以下三個方面的設想,並且付諸了實踐。
首先,通盤考慮日本漢文古寫本整理規範和數據庫建設規範。日本漢文古寫本數據庫建設的目標,是將整理好的古籍數據結構化後用數據庫進行管理和利用。也就是説數據庫的管理對象數據是專家們對典籍進行整理所産出的成品數據。如果在古籍整理階段就考慮數據庫建設的需求,就能够將專家們的産出數據既利用於古籍出版,又作爲數據庫的輸入數據,這樣可達到事半功倍的效果。因此,在制定古籍整理規範的時候,我們除了將古籍整理應遵循的一般規則納入了規範之外,還根據數據庫建設的需要對成品數據的保存規格、書志資訊和校注資訊等各項内容的標注格式及其實現方法進行了規定。這樣可以確保專家們提供的古寫本整理數據既可以順利地導入到數據庫中,也可以直接用於出版環節,同時也盡可能減少了專家們在整理古籍時的工作量。
第二,實現文本内容和PDF格式的對應,同步呈現檢索命中對象的文本資訊和對應内容的PDF格式資訊。典籍整理後的成品是以PDF格式呈現的,也是出版物的最終形態。學者們對整理後的典籍進行研究、利用和二次開發時,主要依據典籍的出版形態。但是,利用電腦對典籍内容進行全文檢索的對象是文本數據,也就是典籍中的文字。因此,在實現全文檢索功能時,需要將文字内容從與實物一致的、帶格式的實物内容中分離出來。一旦表示内容的文字從帶格式的數據中分離出來,很難再恢復成原始格式。這也是爲什麽《中華經典古籍庫》等數據庫的全文檢索結果只有文字、没有格式,不能看到古籍整理專家的成果的原因了。目前,常用的文字編輯工具(如WORD或WPS)和PDF瀏覽工具(如ACROBAT READER)對單個的獨立文本都可以呈現出與出版物一致的形態,即都是所謂所見即所得的工具,也可以在實物内部進行全文檢索。但是,這些工具都是針對單個文本的,不能够作爲數據庫内容的瀏覽工具,更不能遠程訪問數據庫和實現連綫瀏覽。我們建設的是日本漢文古寫本整理後的文獻數據庫,該數據庫將保存大量的、整理好的成品文獻的電子版本,並將在Web平臺上提供遠程訪問服務。這些功能是上述現有的文字編輯、瀏覽、出版工具都無法實現的。
第三,爲了實現古文獻的全文檢索並以出版物形態同步呈現檢索結果,我們使用PDF、DOCX等數據格式的還原技術,將文本數據和PDF格式數據以頁爲單位對應起來,實現檢索時命中的内容和對應的文獻整理後的形態關聯呈現,需要時可以將文獻原始圖片一併呈現出來。具體做法是,古文獻整理專家按照事先規定好的文獻整理規範用WORD等編輯工具製作文獻的DOCX檔,數據庫建設團隊將專家們提交的DOCX檔進行技術處理,按照微軟公司和ADOBE公司公開的DOCX、PDF檔的技術規範,將DOCX檔以頁爲單位將其分解成兩部分,一是文本數據,用於全文檢索;二是對應的PDF格式,用於檢索結果的實物呈現。然後將這兩部分内容分别用數據庫進行管理。以下爲我們所實現的古文獻數據庫的全文檢索結果:

第四,利用正則運算式實現古文獻全文内容的高效檢索,提高命中效率。由於自然語言處理技術的進步,實現現代漢語智能化檢索的方法比較多。但是,古代漢語智能化處理缺乏研究,因此對古代漢語進行智能化檢索的技術手段相當匱乏。我們只能在字元搜索的技術層面,利用現有的技術,盡可能地想辦法提高古代漢語的檢索效率,爲此,我們導入了正則運算式檢索技術。
第五,正則運算式原本是爲了電腦軟體設計人員高效發現電腦程式中的錯誤而設計的一種搜索技術。正則運算式通過規定一些具有特殊功能的符號,利用這些符號的組合(正則運算式)達到檢索特定字串的目的。正則運算式有非常强大的表達能力,被證明是實現字元級别檢索的有效工具。古代漢語一般是字本位的,字和詞往往是統一的,而漢字在電腦中又和字元是統一的,因此從這個角度講,正則運算式也許是古漢語檢索的利器。我們開發的日本漢文古寫本數據庫檢索工具全面支持正則運算式檢索,這裏舉一例説明正則運算式的使用。古籍整理中引用其他典籍的地方比較多,這些被引用的典籍通常用書名號(《 》)括起來,假設我們要檢索二字或者三字書名的文獻時,可以利用正則運算式《.{2,3}》檢索全文數據,下圖爲所得結果的一部分:

結束語
古典文獻數據庫建設往往發端於某一目的,但是作用絶不限於某一領域,其影響範圍往往會超過設計者初始的想象,這也是大數據和數據庫建設的魅力之所在。隨著手機、電子書等便携智能閲讀終端的普及、移動互聯網速度的提升,古籍數據庫無論在學術研究領域,還是服務普通讀者方面,都會得到越來越多的應用。因此,我們在建設古文獻數據庫時,一定要將目光放得長遠一點,絶不能局限於一個目的,要能够從多個領域甚至要從無法預測的使用需求出發考慮數據的結構化問題和數據庫的功能,否則將會造成資源的浪費。就目前的電腦技術水準而言,漢文古寫本數據的智能處理能力還非常有限,這就需要資訊處理技術人員和古籍整理專家充分溝通協調,使古籍整理專家們的辛勤勞動盡可能地發揮作用。本文在現有的技術水準下,探討了古文獻數據庫檢索結果的文本數據和實體數據的同步呈現、以及利用正則運算式實現古籍全文數據的高效檢索問題。但是,將現代資訊技術引入到古典文獻整理研究所面臨的難題還很多,需要古文獻專家和電腦科學家的共同努力。