(1.湖南省少年儿童图书馆,湖南 长沙 410005;2.湖南图书馆,湖南 长沙 410011)
图书流通工作是图书馆服务效能的重要指标,也是密切反映读者需求的重要途径。通过对图书流通情况的分析,运用计算机将这些指标把图书在图书馆中被利用的情况反映出来,图书馆可以从中得出图书馆读者的阅读倾向与需求目标,在此基础上的研究对今后的采购与藏书更有指导性的意义。图书流通量是一个量化的绝对指标,客观地反映出图书流通借阅的情况,同时也反映出图书实际的利用水平和程度,真实地反映了图书馆工作的业务水平。每一个图书馆都希望能获得图书流通量的趋势,如果能预测图书流通量,那么对图书馆制定馆藏体系、新书采购计划、借阅流通资源管理以及人员服务管理来说都有着积极的意义。由于图书需求量变化响应的非线性和不连续性特征,很难用传统的数学模型进行预测,人工神经网络具有强大的非线性映射能力,在模式识别和非线性预测中都有广泛的应用。
近几年来,人工神经网络发展迅速,由于其自身具有学习和强大的适应能力,已成为比较理想的非线性建模方法。在实际应用过程中,一些对象具有复杂的不确定性、实时性、高度的非线性,这些因素必然造成很难建立一个精确的数学模型,然而人工神经网络却具有逼近、拟合非线性关系的能力,可以帮助解决存在的问题。当前,由于图书馆流通量预测是一个多变量的问题具有非线性、大滞后性的特点,而人工神经网络具有强大的自适应能力,同时具备很强的非线性映射能力,所以本文采用人工神经网络建模来实现对图书流通量的预测估计。我们以两层前径向基函数网络对湖南省少年儿童图书馆2015—2016年相关日期的流通量作为预测样本。
1 建立基于人工神经网络的图书需求量模型
1.1 人工神经网络预测模型
从图书的流通本质出发认识和解决问题的一种研究模型需要有扎实的基础知识,并且了解图书需求量,准确地找出主导变量及有关辅助变量的数学逻辑关系,以数学算式的表达方式进行计算。人工神经网络预测模型结构及工作原理是使用Matlab7.0工具箱函数newrb建立一个径向基函数(Radial Basis Function,RBF)网络,利用该RBF网络建立一个图书流通量预测的模型,此模型具备较强的逼近和非线性处理能力。当然影响图书流通量的因子很多,主要可以分为两个方面:定性和定量。定性方面主要包含藏书体系和馆藏揭示质量、文献借阅方式、学科和专业设置、科研学术氛围、馆员服务与管理水平等;定量方面主要有馆藏数量、读者用户数量、开放时长、年均新书量、借阅册次和期限等。这些因子从不同的角度和方式影响着图书的流通次数。本文用出版社和图书分类号作为RBF网络模型的输入,流通量作为网络模型的输出,初步建立一个基于RBF网络预测图书馆需求量的模型。
1.2 径向基函数(RBF)网络
RBF网络的神经元模型,如图1。RBF的传递函数就是高斯函数,它是以权值和阈值向量之间的距离作为(‖dist‖)为自变量的,‖dist‖是通过输入向量和加权矩阵的行向量的乘积得到的。径向基网络传递函数的原函数为:radbas(n)=e-当输入自变量为0时,传递函数取最大值为1,随权值和输入向量之间距离的减少,网络的输出时递增的,b时阈值,用来调整神经元的灵敏度。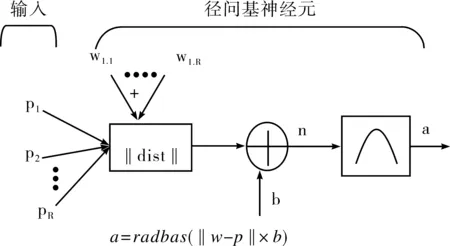
图1 RBF网络神经元模型结构
1.3 径向基函数网络结构
RBF最简模式包括三个层次。第一层为输入层,是由信号源节点而组成;第二层为隐含层,节点函数为高斯函数;第三层为输出层。网络结构形式如图2所示。本文的神经网络输入层节点为l8个,输出层有4个结点,隐含层的结点数需在模型调试后才能确定。各层之间的神经元无连接,各层内也没有连接。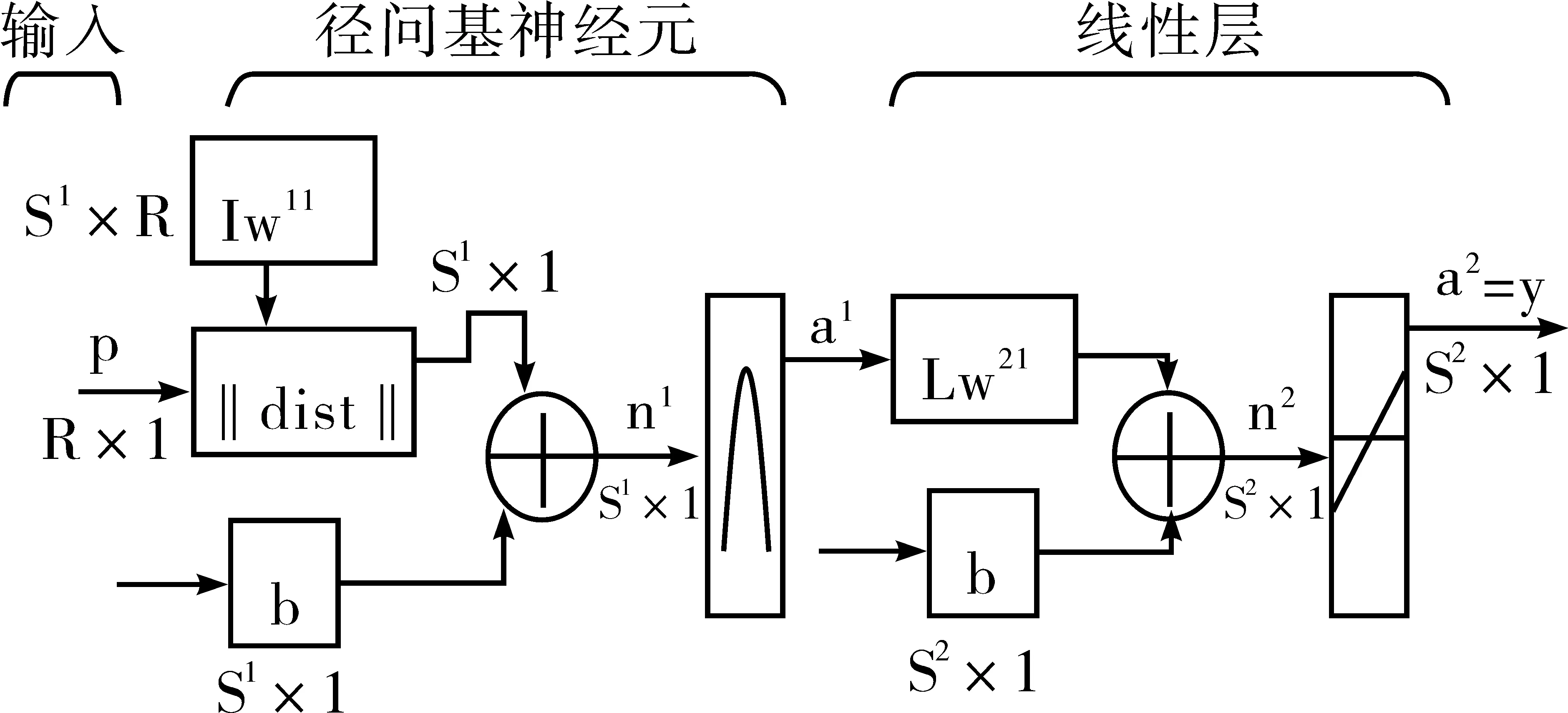
图2 RBF网络结构形式
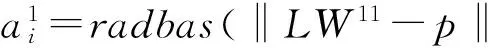 ‖dist‖模块计算输入R维向量p和输入权值IW的行向量之间的距离,产生S维向量,然后和阈值b相乘,再通过径向基传递函数得第一层输出a,最终输出层得输出为:a=purelin(LW
‖dist‖模块计算输入R维向量p和输入权值IW的行向量之间的距离,产生S维向量,然后和阈值b相乘,再通过径向基传递函数得第一层输出a,最终输出层得输出为:a=purelin(LWa+b)。
1.4 RBF的工作原理
REF神经网络中有两类待确定的参数,一种是基函数中心点,另一种是宽度以及网络的权值。所以,我们模型的学习过程就分为两步走,第一步确定中心点及宽度,第二步就是权值的学习。当然第一步的确定是网络模型性能的关键一步。本文采用Moody和Darken的学习算法(M&D算法),整个训练学习过程分为两个阶段:非监督学习和监督学习。非监督学习采用的是K-means聚类方法,这种算法是对训练样本的输入量进行大量的聚类,从中找出聚类中心点Ci及参数σi,之后再进入监督学习的阶段。当中心点Ci及参数σi确立以后,REF网络就会从输入到输出形成一个线性方程组,从而在监督学习阶段就可以采用最小二乘法,解出网络模型的输出权值ωi。M&D算法中的K-means聚类算法,需要在事前就确立好中心点的个数,这种算法给不熟悉神经网络模型的用户带来一些不便,中心点个数确定不合适,就有可能会对网络模型造成一定影响。因此本次研究确定中心点是采用无监督聚类最近邻聚类算法(Nearest Neighbor-Clus-tering Algorithm),这种算法并不需要事先确定中心点个数,就可以构建出比较理想的网络模型,更加适合本次研究,满足实时样本数据自动构建网络模型的要求。
2 基于人工神经网络的图书馆需求量模型实验
2.1 图书馆需求量模型流程

图3 图书需求量模型建立流程图
图3给出了对图书流通量预测的流程,从流程上我们看出,首先是要对样本数据进行分析,包括对输入、输出量的选择,数据准备及预处理。完成了对样本数据分析后,接下来是网络模型的建立,也就是确定输入层、隐含层及输出层的全部过程,模型建立完成之后,就可以对网络模型进行学习训练了,之后再利用训练好的网络模型对流通量进行预测估计。
2.2 数据的选取
本研究采用湖南省少年儿童图书馆2015—2016逐年平均日流通量,从ILASⅢ(图书馆自动化管理系统)的流通管理中获取流通量原始数据,对数据进行分析后,估计图书的流通量,指导新书采购的复本量,从而得出图书的需求量。数据从ILASⅢ中的流通管理子系统的图书排行榜统计流通借阅量。部分流通量数据如表1所示。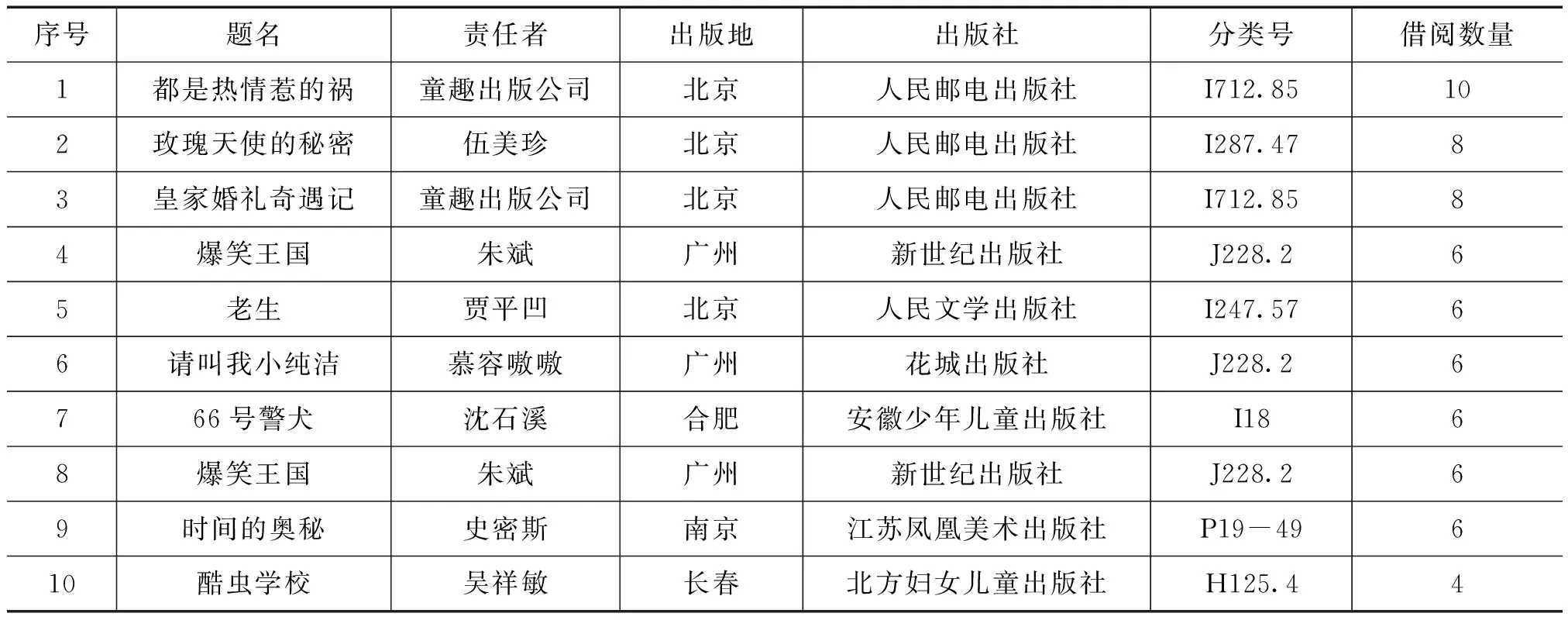
表1 部分流通量数据
由于本文研究的是图书流通量预测估计问题,模型最后输出结果为预测的图书流通量。在实际图书流通工作中,很多因素都和图书流通量密切相关。这些因素不仅涉及流通管理中的各个环节,而且这些环节中的各种因素是复杂的非线性关系。在建立网络模型的过程中,如何选择输入变量将直接影响预测估计模型的准确性。
在选择图书流通预测估计模型的输入变量时,首先选择的输入变量必须符合流通工作的实际情况,同时根据图书采购的特点进行一些选取,减少采购人员的主观购书。人工神经网络预测模型是个多个输入、输出的模型,如果输入变量过多,导致网络预测估计效果并不会很好。所以我们在选取输入变量时,要根据预测估计模型自身的特点,尽可能选择一些包含信息量比较大的综合型变量和对图书流通量影响较大且客观的变量。我们最终选择出版社和图书分类为网络的输入变量,日实际流通量为网络的输出变量。
2.3 数据的准备
在对图书流通量预测估计之前,数据的准备工作是非常重要。经过正确适当处理的数据,将对预测估计结果的准确性产生良好的效果,相反将会导致预测结果不理想。数据准备工作中首先选择恰当数量的训练学习的样本数据,如果选取样本过少,那么模型就得不到训练所需的足够信息;但是如果选取太多,那么会导致网络训练时间增加,从而导致网络模型的运行恶化。所以我们要根据实际情况正确选取训练样本数量。在数据准备中还有一个方面也要注意,不能存在互相矛盾的数据,两个样本如果存在影响因素相同,但是目标数据不同,那么这说明两个样本之间是相互矛盾的,这种矛盾可以通过增加因素或者直接删除来解决。本次研究将出版社和图书分类为网络的输入变量,月实际流通量为网络的输出变量。我们将出版社和图书分类用数值代替,处理前进行归一化处理,随机选1/2做训练样本,训练网络,1/4做检验数据,1/4做预测数据。2.4 实验结果
使用Matlab 7.0工具箱函数建立一个RBF网络,从输入层到隐含层,采用的是一种自我适应聚类的算法,这种算法并不需要事先确定隐单元的个数,完成聚类所得到的RBF网络是最优的算法。此算法选择一个适合的高斯函数宽度R,取第1个样本作为一个聚类中心,令C1=X1计算样本1与样本2间的距离,若|X1-X2|≤R,则X2为X1的最近邻聚类;若|X1-X2|>R,则将X2作为一个新的聚类中心;当取第K个样本时,已有M个中心了。那么就分别计算XM与这M个样本的中心距离,若|Xk-Xi|是距离中最小的,那么Xi是Xk的最近邻聚类,若|Xk-Xi|>R,那么Xk作为一个新聚类中心,设定平方和误差参数为0.001,同时完成网络模型的训练学习;仿真网络学习是通过使用sim函数,产生关联的网络输出值,并绘出相关的曲线图。训练前要求要提供输入矢量、对应目标矢量与径向基函数的扩展常数C。在本次试验中对径向基函数的扩展常数C值我们选1、3、6、9、14、20、进行比较,以获得最佳C值,达到较快的速率与较好的精度。目标误差是0.001,对网络的输出矢量与目标矢量进行训练样本的误差分析,用建立的网络,进行仿真,对网络的输出矢量与目标矢量进行检验样本的误差。分别见下图。我们比较图6、8、10、12、14、16,不同C值的检验误差,可以判断在C为3时的效果最好,其检验误差在0.005左右。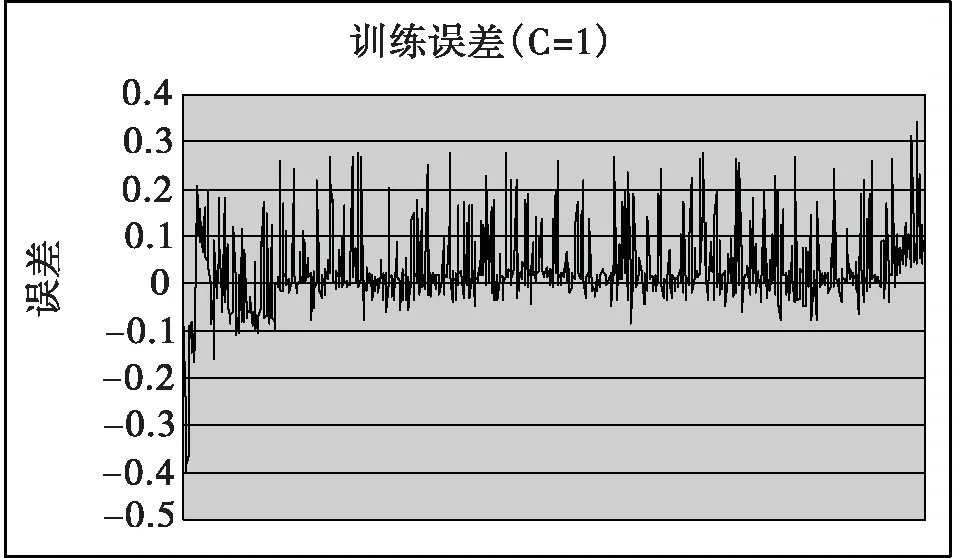
图5 训练误差曲线(C=1)
图6 检验误差曲线(C=1)
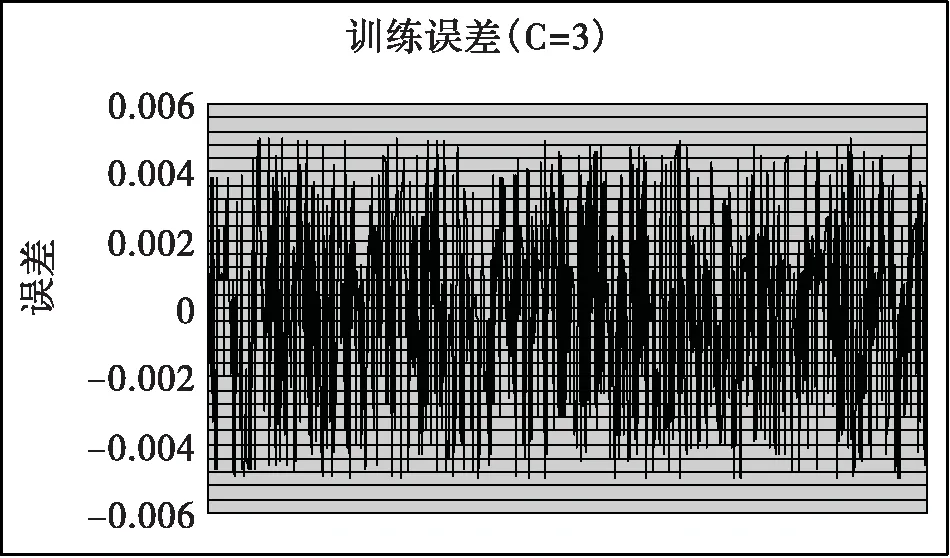
图7 训练误差曲线(C=3)
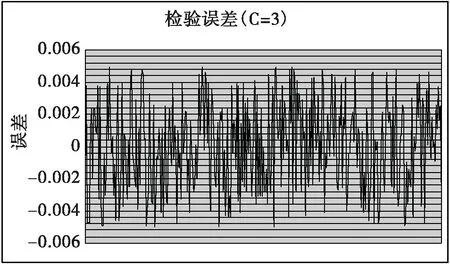
图8 检验误差曲线(C=3)
图9 训练误差曲线(C=6)
图10 检验误差曲线(C=6)
图11 训练误差曲线(C=9)

图12 检验误差曲线(C=9)
图13 训练误差曲线(C=14)
图14 检验误差曲线(C=14)
图15 训练误差曲线(C=20)
图16 检验误差曲线(C=20)
2.5 所建模型的应用
用“save netoknet”,命令把训练好的神经网络固化到netok.mat中,调用时,用“load netok”,其中环境中“net”为所训练的网络。其网络结构如下:结构属性(architecture):
输入向量数目(numInputs):1
网络层数(numLayers):2
阈值连接属性(biasConnect):[1;1]
输入连接属性(inputConnect):[1;0]
层连接属性(layerConnect):[0 0;1 0]
输出连接属性(outputConnect):[0 1]
期望输出向量连接属性(targetConnect):[0 0]
子对象属性(subobject structures):
输入向量(inputs):1x1的细胞矩阵
网络层layers:2x1的细胞矩阵
输出层outputs:1x2的细胞矩阵,包含1输出
期望输出向量targets:1x2的细胞矩阵
阈值向量biases:2x1的细胞矩阵包含2个阈值
输入权值inputWeights:2x1的细胞矩阵包含1个输入权值
层权值layerWeights:2x2的细胞矩阵
权值和阈值属性(weight and bias values):
输入权值矩阵IW:2x1的细胞矩阵
层间权值矩阵LW:2x2的细胞矩阵
阈值向量b:2x1的细胞矩阵包含2个阈值向量
由表2可以看出,对高流通的书估计还不准确,对低的流通量的书,预报误差较小,性能可以满足实际应用的需要.其对高流通的书估计不准确的原因可能由于样本的选择受干扰,而未包括全部可能的模式。设计训练样本时。将样本的模式集中于这一区城,网络对这一区域的预测可达到很高的精度。但是网络投入使用后,其他使用者可能会发现网络对其他区域的预测精度很低。高流通量的书比例少,如流通量在7次以上,仅占0.083%,我们又采用随机抽样,导致含高流通量的书训练样本少,导致准确度不高。要注意在选择训练样本时,各种可能模式间的平衡。训练样本中不仅要包括每种类型,而且每种类型所具有的训练样本数要平衡,不能偏重于某种类型。
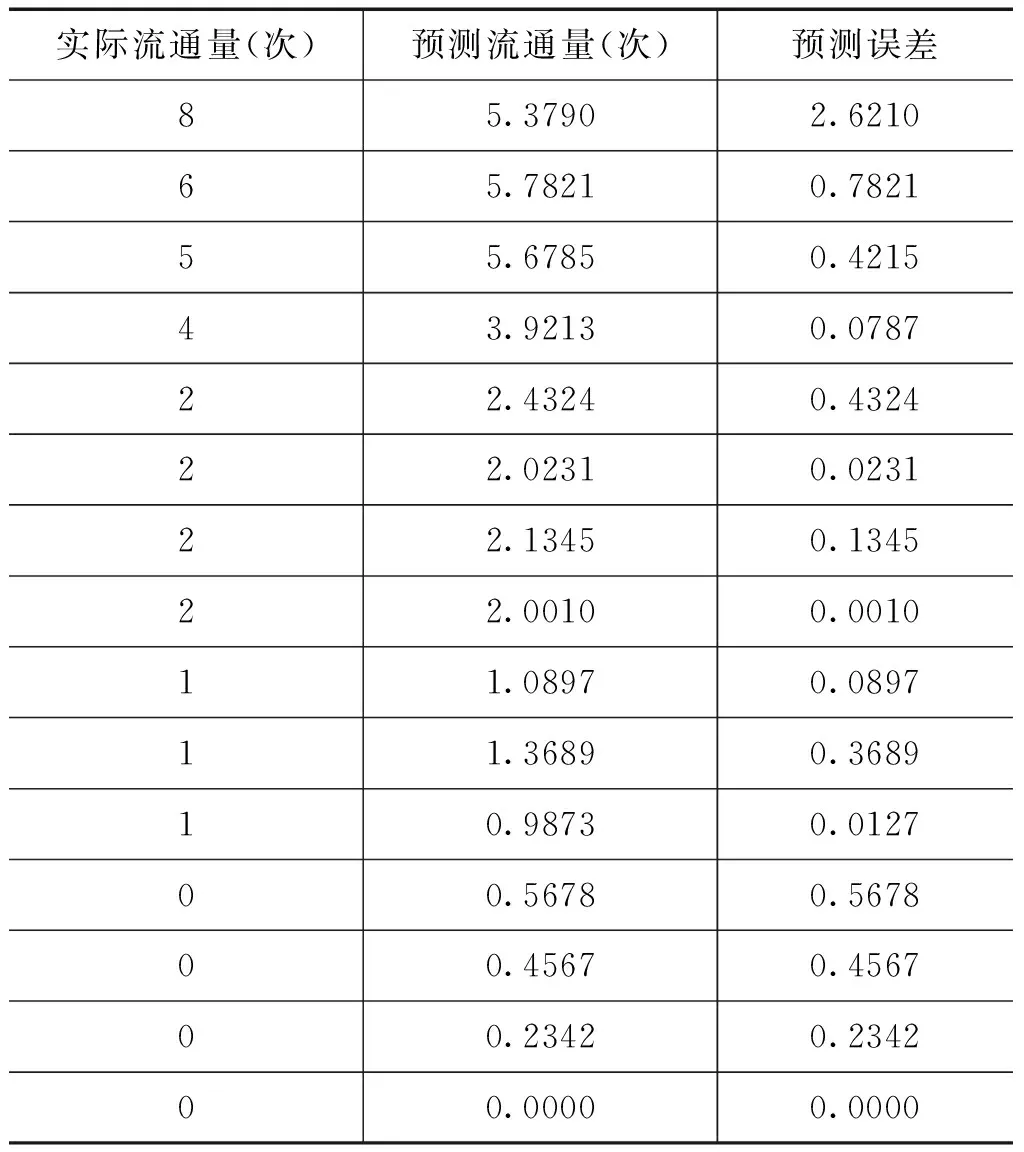
表2 预测误差
图书流通量预测是一个复杂的、非线性的过程,我们必须寻找适合非线性的手段来开展研究工作。用径向基函数网络建模来实现对图书流通量的预测估计,从模型得出的结果与实际观测值对比,还是具有比较高的预测精度。用人工神经网络法进行预测时,并不需建立复杂的显性关系,一些非专业人员只要对数据进行简单的预处理,就可以建立一个预测估计模型,方法非常简便实用。本文的研究结果仅仅是一个开始,如何在实际流通、采购过程中使网络模型更加本地化、更具针对性,需进一步的研究,从而进一步提高图书流通量的预测精度。
3 结 语
本文首先从ILASⅢ提取流通数据,并随机选取了湖南省少年儿童图书馆 5 000 种图书在2015—2016年度的平均日流通量数据,然后对现有数据库进行了筛选、分析和研究。在此基础上,把出版社和图书分类作为网络的输入变量,把实际流通量为网络的输出变量。将出版社和图书分类用数值代替,处理前进行归一化处理,随机选1/2做训练样本,训练网络,1/4做检验数据,1/4做预测数据。对网络的输出矢量与目标矢量进行训练样本的误差分析,用建立的网络,进行仿真,对网络的输出矢量与目标矢量进行检验样本的误差分析。我们通过使用图书流通量的实际数据,运用RBF网络进行了图书需求量模型预测。从实验结果来看,取得了比较理想的结果,说明该模型用于图书需求量预测是可行的,具有一定的参考意义。
[1]朱轶婷,李 霖,韩玉巧.利用流通数据指导制定文献资源建设策略的实证研究——以中国民航大学图书馆为例[J].图书馆杂志,2016(12):48—54.
[2]刘 涛,闫其春.一种基于本体的图书馆绩效评价模型[J].情报探索,2016(4):67—70.
[3]李国辉.基于权值直接确定神经网络的采购提前期预测模型[J].科技风,2016(6):24—25.
[4]范一文.基于径向基函数神经网络的高校图书馆用户满意度评价模型[J].农业图书情报学刊,2016(3):10—13.
[5]蒋鸿标.我国图书馆纸本藏书评价理论研究述评[J].图书馆,2016(5):55—60.
[6]叶兰平,刘 锋,朱二周.基于径向基神经网络的新型协同过滤推荐算法[J].计算机应用与软件,2016(11):180—184.
[7]龙 亿,杜志江,王伟东.GA优化的RBF神经网络外骨骼灵敏度放大控制[J].哈尔滨工业大学学报,2015(7):26—30.
[8]刘志刚,许少华,李盼池,等.基于极限学习离散过程神经网络的示功图识别[J].信息与控制,2016(5):627—633.