所谓自然语言处理主要指的就是,针对人和计算机这两者之间通过自然语言展开合理通信与交流的理论与方式展开详细研究,其不仅可以为计算机技术的发展起到一定程度的推动作用,还可以为Artificial Intelligence技术的发展起到一定的完善作用,属于一门将语言、计算机、数学相互结合而来的学科。由于如今计算机网络中的信息资源一直处于持续增加的状态,导致互联网中所储存的信息数据较为庞大,在针对其中的信息数据展开有效处理时,对于计算机的中央处理器与服务器等部件而言都是一种挑战,于是就开始在对信息数据展开处理时,经常会在速度、空间与容错性等多方面出现问题。而MapReduce这种编程模型的诞生,不仅能够优化计算机中的配置,也能够提升计算机处理信息数据的实际效率,因此,就需要针对自然语言处理中MapReduce原理的实际应用展开详细分析,从而确保在如今时代下,对于自然语言处理的准确性与稳定性。
一、MapReduce原理的主要概述
MapReduce自身属于一种在编程时所应用的模型,通常都是应用在实际规模较大的数据集并行与计算中,其在工作过程中的主要原理如图1所示: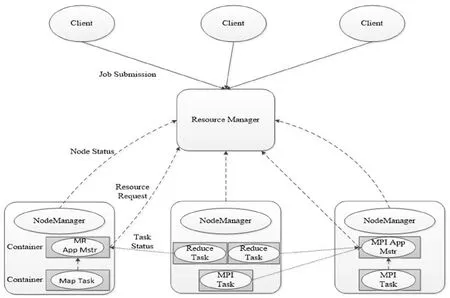
图1:MapReduce的工作原理
在MapReduce其中的Map所代表的映射,而Reduce所代表的是归约,这两者中所蕴含的核心理念都是由编程语言中的函数而来,还具有一些编程语言中矢量特性【1】。在MapReduce中的主要原理在于,集合相关用户所定义key与value对的输入处理,再根据中间输出集合key与value对,并将中间完全相同的key与value相互集合后,传输到MapReduce的函数之中,然后在其中的函数就能够讲完全相同的key与value相互合并,最终形成value值较小的集合【2】。在MapReduce这种编程模型实际展开运行的过程中,主要涵盖了:对大量的输入信息数据划分交由多个计算机对其展开处理、通过worker将所有输入的信息数据分为key与value、通过函数将所有输入信息数据中的key与value转换为中间形式、根据key的实际值排列出中间形式中的key与value、将各不相同的key与value交由各不相同的计算机、对Reduce展开实际计算、最终得出Reduce的计算结果【3】。
二、MapReduce原理的格式种类
通过MapReduce所构建的信息数据模型会较为简单,因为在其中Mao与Reduce的有效函数,能够充分利用key与value展开合理的输入或是输出,但一定要严格遵守相应形式【4】。如以下所示:Map=(k1.v1)→ list(k2.v2)
Reduce=(k2.list(v2))→ list(k3.v3)
在MapReduce这种模型库中,对于多种格式有所不同种类的输入数据会提供一定的支持,例如:在文本类型的输入数据中,每行都会被当做一对key与value,在这其中key所代表的是文本文件所出现的偏移量,而value所代表的是在整个文本中此行的实际内容。而且在MapReduce中预定义类型的输入方式,不仅可以在真正意义上满足多种输入的实际需求,还可以让应用者充分利用MapReduce所提供的简单接口,创新一种全新输入的种类。除此之外,在MapReduce中还包含有预定义类型的输出方式,充分利用就可以制作出格式各不相同的输出数据,而且相关用户还能够通过增加输入数据的种类方法,对输出数据的种类方法展开合理、有效的增加【5】。
三、自然语言处理中MapReduce原理的实际应用
1、索引及MapReduce的构建
构建索引系统是信息检索系统中最为重要的阶段之一。在信息检索领域中,创建大规模语料库搞笑的索引是目前而言较为困难的问题之一,而通过使用分布式狂阶对广泛的文本语料库展开与行化索引,是创建较为合适的索引以及可以方便展开搜索的有效方式。Jeffrey Dean与Sanjay Ghemawat共同完成的Mapreduce学术论文中曾经给出的索引策略是:map函数解析每个文档,输出的一系列word、documentID对,reduce函数的数据属于一种给定word相应的文档ID,输出一个《word、document ID》对,所有输出集合形式就可以形成一个较为简单的倒排索引,这样一来通过一种较为简单的算法就可以准确的寻找出跟踪词在文档中的具体位置。这种策略虽然只是简单的描写出了运用MapReduce构建索引的方式,但是却说明了运用MapReduce可以实现大规模银锁构建的可能性,同时也会为相关研究人员在MapReduce中实现文本索引的研究提供了较为有益的研究空间。基于MapReduce模型可以充分实现构建索引,在实际构建的过程中策略为:map函数为文档中的词,输出一个文档ID对,reduce函数将相同的文档ID展开合并,通过合并的方式获得项频率。这种策略的最大优点是map阶段较为简单,通过将每个词作为输出基础的同时,确保基础的准确性与稳定性。但是一旦出现一个词在某个文档中出现tf次时,就会促使文档ID中的输出次数转变为tf次。这样一来就会促使map的数据不断增加,因为语料库中的每一个词都会自动升恒一个文档ID,所以当map任务输出在多数中间数据中时,这些中间数据就会被全面的保存在设备的本地磁盘C中,而后再通过传输的方式传输给更加合适reduce任务。大量的map中间数据会不断增加map至reduce传输过程中所使用的网络流量,同时还会最大几率的延长排序阶段,这些因素最终就会对实际执行的时间造成影响【6】。2、 聚类算法及Mapreduce
聚类算法属于一种非监督形式的学习方式,并且该种方式在多数应用中已经被基于广泛的关注与重视,例如:数据挖掘、文档搜索、模式识别、机器学习等。在处理大规模数据的过程汇总,传统的串行聚类算法因速度较慢并且效率较低,就会导致无法充分满足实际应用的要求,这一因素也是导致大规模数据聚类成为一项具备较高挑战性工作的主要原因,为了可以有效解决这一问题,就需要通过全面研究的方式,通过研究来设计出高效率、高质量的并行聚类算法。Mapreduce编程模型作为一种具备较强分布式计算的乱加,其可以被广泛应用到数据聚类领域。通过实际研究可以充分实现基于Mapreduce的并行K-Means聚类,Map函数执行每一个对象到距离自身最近的聚类中心程序,Reduce函数可以执行更新聚类中心的程序。浙江大学的温程在其说是学位论文中,充分研究出了两种Mapreduce的聚类算法,分别是并行化谱聚类与并行化AP聚类。并行化谱聚类算法的主要策略是通过计算相似矩阵及稀疏化时根据数据点标识展开切分;在计算特征向量时可以通过讲拉普拉斯矩阵存储到分布式文件系统HDFS上的方式,并通过分布式Lanczos来展开运算,最终得到并行计算的实际特征向量;当通过特征向量的转置矩阵采用并行K-means聚类时,可以得到准确的聚类结果。并行化AP聚类的策略主要是先将吸引度矩阵与归属度矩阵分布式储存在HB阿瑟上,将每次迭代中度吸引度矩阵与归属度矩阵的实际计算通过分割的方式展开,并使其矩阵制的实际运算根据行分布的多台机器上展开运算【7】。3、文本分类及Mapreduce
文本的分类是一种具备监督设备学习的有效方式,其主要是基于文本中的内容讲待定的文本实际划分到单一或多个预定的类别中。最初是由Google实验室所提出的MapReduce秉性分布式计算模型,其主要是针对海量数据展开处理,网络文档属于一个海量数据集,MapReduce编程模型更加适合对大型规模的网络文档自动分类工作。特征的选择属于文本分类中的一种预处理步骤,其可以充分提文本分类的有效性与效率,多数设备中的学习算法在多数程度上会受到来自文本特征选择的影响,并且还会直接影响到文本分类的具体运行情况。大规模文本分类特征属于一种高维度的问题,在并行执行特征的选择中可以充分实现并行化的运行,在实际研究的过程中可以通过并行运算的方式来提高统计特征的实际选择效率。在实际运用余弦定理来计算文档之间的相似度时,可以根据相似度对文档展开分类,在计算文本相似度的过程中,TF-IDF(term frequency-inverse documet frequency)权重计算方式可以起到即为关键的作用。通常情况下TF-IDF会经常性的被应用到搜索引擎中,将其作为用户与文件查询之间的相关程度评级以及度量,但是因为实际计算量较大,就需要通过应用Mapreduce来解决TF-IDF中存在的计量大且速度较慢等问题。在实际针对目前弹击中较大的文本自动分类训练时,实际分类训练的时间较长,而在相关研究中的某种设计可以充分实现基于Mapreduce结构框架的并行贝叶斯文本分类算法,并且可以充分运用三个Mapreduce过程来实现并行贝叶斯文本分类算法的训练。其中,在第一个Mapreduce过程中,每个mapper可以接受来自训练文档中的部分数据块,并且其还可以根据实际训练快来计算出部分训练分档中的词频以及文档的书刘昂,reducer可以针对每个由mapper传输的文档展开计算与统计,并将其存储至相关数据库而后作为中间结果;在第二个Mapreduce过程中,每个mapper所接收的第一步Mapreduce所生成的中间数据,通过词频的方式针对文档展开特征方面的抽取,并将储存后的数据作为中间数据;在第三个Mapreduce过程中,每个由mapper所接收的第二步Mapreduce中间数据,通过实际计算之后可以得出各类别的先验概率,同事还可以通过文档中的名词特征来展开分析,最终就可以得到完整度较高的贝叶斯分类模型【8】。结束语:
综上所述,MapReduce自身属于一种编程模型,其不仅能够针对大量的信息数据展开有效处理,还能够从大量的信息数据中及时找到最有价值的相关数据。在MapReduce这种编程模型中,将容错、负载平衡、同步处理等相关技术中的难点与细节完全封装,即使是自身缺乏开发相关系统经验的编程人员,也可以轻易的驾驭并应用这种MapReduce模型。在如今时代下,这种MapReduce的相关原理已经开始在社会各领域广泛应用,但如今针对MapReduce这种模型的主要研究几乎都在其的实际应用中,针对计算方式与实际效率等方面的优化研究几乎是少之又少,因此,就需要加强对于MapReduce计算方面的研究力度,从而为MapReduce的后续发展打下较为坚固的基础。